목차
RFM 분석이란?
The look ecommerce 데이터로 RFM 분석 실습
a. Recency 구하기
b. Frequency, Monetary 구하기
c. Recency, Frequency, Monetary 한번에 구하기
RFM 스코어링
a. Recency 스코어링
b. Frequency, Monetary 스코어링
c. 최종 RFM 스코어링
d. 최종 RFM 점수를 평균으로 구할 때 주의할 점태블로로 RFM Tree Map 구현하기
더 생각해보기
참고자료
서비스를 이용하는 고객의 특성을 분류할 수 있다면,
서비스 사용자에 대한 이해를 넓힐 수 있다.
특히 마케팅 담당자라면 그룹별로 개인화된 혜택을 제공하여
더 뾰족한 타겟 마케팅을 활용할 수 있을 것이다.
이번 시간에는 고객 행동을 분석할 수 있는 가장 인기 있고
효과적인 세분화 분석 중 하나인 RFM 고객 세분화 분석에 대해 알아보고,
예시 데이터를 통해 RFM 분석이 어떻게 작동하는지 알아보도록 하겠다.
RFM 분석이란?
RFM은 가치 있는 고객을 추출해 Recency, Frequency, Monetary를 기준으로
고객을 분류할 수 있는 분석 방법이다.
- Recency - 제일 최근에 구입한 시기가 언제인가?
- Frequency - 어느 정도로 자주 구입했나?
- Monetary - 얼마나 많은 금액을 주고 구입했나?
Frequency와 Monetary는 고객 생애 가치(CLV)
즉, 고객이 우리 서비스를 이용하는 총 기간 내에 이익을 주었는지를 계산한 것에 영향을 미치고
Recency는 서비스를 지속해서 사용하는지의 리텐션에 영향을 미치기 때문에
이러한 RFM 측정 항목은 고객 행동을 나타내는 중요한 지표이다.
한편, 시청률, 독자층 또는 서핑 중심의 제품을 다루는 비즈니스는
금전적 요소 대신 이탈률, 방문 기간, 페이지당 소요 시간 등 인게이지먼트와 같은
측정항목을 기반으로 하는 RFE(Engagement)가 사용될 수 있다.
RFM 분석을 통해 다음과 같은 사실을 알 수 있다.
- Recency - 최근 구매일 수록 프로모션에 대한 고객의 반응이 더 좋아진다.
- Frequency - 고객이 더 자주 구매할 수록 고객의 참여도와 만족도가 높아진다.
- Monetary - 금전적 가치는 지출이 많은 구매자와 가치가 낮은 구매자를 구별한다.
RFM 분석은 주로 할인 문자, 카카오톡 메시지 등
고객을 세분화하여 효과적으로 고객의 반응을 이끌어내는
CRM(Customer Relationship Management) 마케팅에 활용할 수 있다.
The look ecommerce 데이터로 RFM 분석 실습
그러면 이제 실제 데이터로 실습을 해보면서
RFM이 어떻게 작동하는지 살펴보도록 하겠다.
사용할 데이터는 Google Looker 팀이 개발한
가상의 이커머스 의류 매장 The look의 이커머스 데이터이다.
이번 RFM 분석은 가치 있는 고객을 추출해
각 세그먼트별로 뾰족한 CRM 마케팅을 적용하는 것을 목적으로 삼고자 한다.
데이터에 대한 상세한 정보가 궁금하다면 아래의 링크를 참고 부탁한다.
Google 클라우드 플랫폼
로그인 Google 클라우드 플랫폼으로 이동
accounts.google.com
Recency 구하기
SELECT user_id
, DATETIME_DIFF('2024-02-29', DATE(recent_date), DAY) AS recency
FROM (
SELECT user_id
, MAX(created_at) AS recent_date
FROM bigquery-public-data.thelook_ecommerce.order_items
WHERE DATE(created_at) < '2024-03-01'
GROUP BY user_id
) recent
분석한 시점인 3월 21일은 아직 3월이 다 지나가지 않은 관계로
2024년 2월 29일을 기준으로 해서 고객별로 마지막 구매일이 몇일 차이 나는지를 구하였다.
Recency의 값이 음수가 나오지 않도록 2월 29일 이후의 구매가 발생한 경우는 제외하였다.

Frequency, Monetary 구하기
SELECT oi.user_id
, COUNT(DISTINCT oi.order_id) AS frequency
, ROUND(SUM(oi.sale_price * o.num_of_item), 2) AS monetary
FROM bigquery-public-data.thelook_ecommerce.order_items oi
LEFT JOIN bigquery-public-data.thelook_ecommerce.orders o ON oi.order_id = o.order_id
WHERE DATE(oi.created_at) < '2024-03-01'
GROUP BY oi.user_id
Frequency와 Monetary는 order_items 테이블과 orders 테이블을 활용하여 한번에 구할 수 있다.
Frequency는 주문한 횟수를 중복 없이 세서 구하였고
Monetary는 (주문 가격 * 주문한 제품 수)의 합을 구하고 소수점 둘째자리까지 나오도록 하였다.
Recency 때와 마찬가지로 2월 29일 이후의 구매가 발생한 경우는 제외하였다.
Recency, Frequency, Monetary 한번에 구하기
위의 결과를 하나의 쿼리로 구현하고 싶다면 아래처럼 짤 수 있다.
SELECT user_id
, DATETIME_DIFF('2024-02-29', DATE(recent_date), DAY) AS recency
, fre_mon.frequency
, fre_mon.monetary
FROM (
SELECT oi.user_id
, MAX(oi.created_at) AS recent_date
, COUNT(DISTINCT oi.order_id) AS frequency
, ROUND(SUM(oi.sale_price * o.num_of_item), 2) AS monetary
FROM bigquery-public-data.thelook_ecommerce.order_items oi
LEFT JOIN bigquery-public-data.thelook_ecommerce.orders o ON oi.order_id = o.order_id
WHERE DATE(oi.created_at) < '2024-03-01'
GROUP BY oi.user_id
) fre_mon
ORDER BY recency
RFM 스코어링
위의 표에서 각 RFM 속성을 기준으로 점수(1~4점)를 매겨
가장 최근 구매자에게 높은 Recency 점수를,
가장 자주 구매한 구매자에게 높은 Frequency 점수를,
가장 많은 금액을 지불한 구매자에게 높은 Monetary 점수를 부여한다.
이중 Recency와 Monetary는 4분위수로 나누어
상위 20%에게 4점, 50%에게 3점, 80%에게 2점, 그 외에게는 1점을 주어 차이를 두었다.
(참고) 4분위를 상위 20%부터 나눈 이유 : 파레토 법칙
파레토 법칙은 이탈리아의 경제학자 빌프레도 파레토의 이름에서 따온 법칙으로
이탈리아 인구의 20%가 이탈리아 전체 부의 80%를 가지고 있다는 내용을 담고 있다.
이는 서비스 분야에 따라 상세 수치의 차이가 있겠지만 서비스 매출에도 비슷한 경향을 보인다.
상위 20%부터 특정 고객층을 나누면 해당 고객층의 특성을 구할 수 있을 것이고,
이는 일반 고객층에도 확대하여 인사이트를 얻을 수 있기 때문에 이와 같이 기준을 정하게 되었다.
Recency 스코어링
WITH rfm_r AS (
SELECT user_id
, DATETIME_DIFF('2024-02-29', DATE(recent_date), DAY) AS recency
FROM (
SELECT user_id
, MAX(created_at) AS recent_date
FROM bigquery-public-data.thelook_ecommerce.order_items
WHERE DATE(created_at) < '2024-03-01'
GROUP BY user_id
) recent
), dense_rnk AS (
SELECT *
, DENSE_RANK() OVER (ORDER BY recency) AS recency_rnk
FROM rfm_r
), pct_rnk AS (
SELECT *
, PERCENTILE_CONT(recency_rnk, 0.2) OVER () AS p20
, PERCENTILE_CONT(recency_rnk, 0.5) OVER () AS p50
, PERCENTILE_CONT(recency_rnk, 0.8) OVER () AS p80
FROM dense_rnk
)
SELECT user_id
, recency
, CASE WHEN recency_rnk <= p20 THEN 4
WHEN recency_rnk <= p50 THEN 3
WHEN recency_rnk <= p80 THEN 2
ELSE 1
END AS recency_score
FROM pct_rnk
ORDER BY recency
Frequency, Monetary 스코어링
WITH rfm_fm AS (
SELECT oi.user_id
, COUNT(DISTINCT oi.order_id) AS frequency
, ROUND(SUM(oi.sale_price * o.num_of_item), 2) AS monetary
FROM bigquery-public-data.thelook_ecommerce.order_items oi
LEFT JOIN bigquery-public-data.thelook_ecommerce.orders o ON oi.order_id = o.order_id
WHERE DATE(oi.created_at) < '2024-03-01'
GROUP BY oi.user_id
), dense_rnk AS (
SELECT *
, DENSE_RANK() OVER (ORDER BY monetary) AS monetary_rnk
FROM rfm_fm
), pct_rnk AS (
SELECT *
, PERCENTILE_CONT(monetary_rnk, 0.2) OVER () AS p20
, PERCENTILE_CONT(monetary_rnk, 0.5) OVER () AS p50
, PERCENTILE_CONT(monetary_rnk, 0.8) OVER () AS p80
FROM dense_rnk
)
SELECT user_id
, frequency
, CASE WHEN frequency = 4 THEN 4
WHEN frequency = 3 THEN 3
WHEN frequency = 2 THEN 2
ELSE 1
END AS frequency_score
, monetary
, CASE WHEN monetary_rnk <= p20 THEN 4
WHEN monetary_rnk <= p50 THEN 3
WHEN monetary_rnk <= p80 THEN 2
ELSE 1
END AS monetary_score
FROM pct_rnk
ORDER BY user_id
참고로 Frequency 값을 살펴볼 때 1, 2, 3, 4번 값만 나와서
차례대로 4번 구매하면 4점,,, 1번 구매하면 1점을 부여하도록 하였다.
이후 두 테이블을 조인 후 csv 파일로 만들어 rfm이라는 테이블을 만들었다.
최종 RFM 스코어링
마지막으로 개별 RFM 속성에 동일한 가중치를 부여하여
RFM 점수의 평균으로 최종 RFM 점수를 구할 수 있다.
SELECT user_id
, recency_score
, frequency_score
, monetary_score
, ROUND((recency_score + frequency_score + monetary_score) / 3, 2) AS rfm_score
FROM `the_look_preprocessed.rfm`
ORDER BY user_id
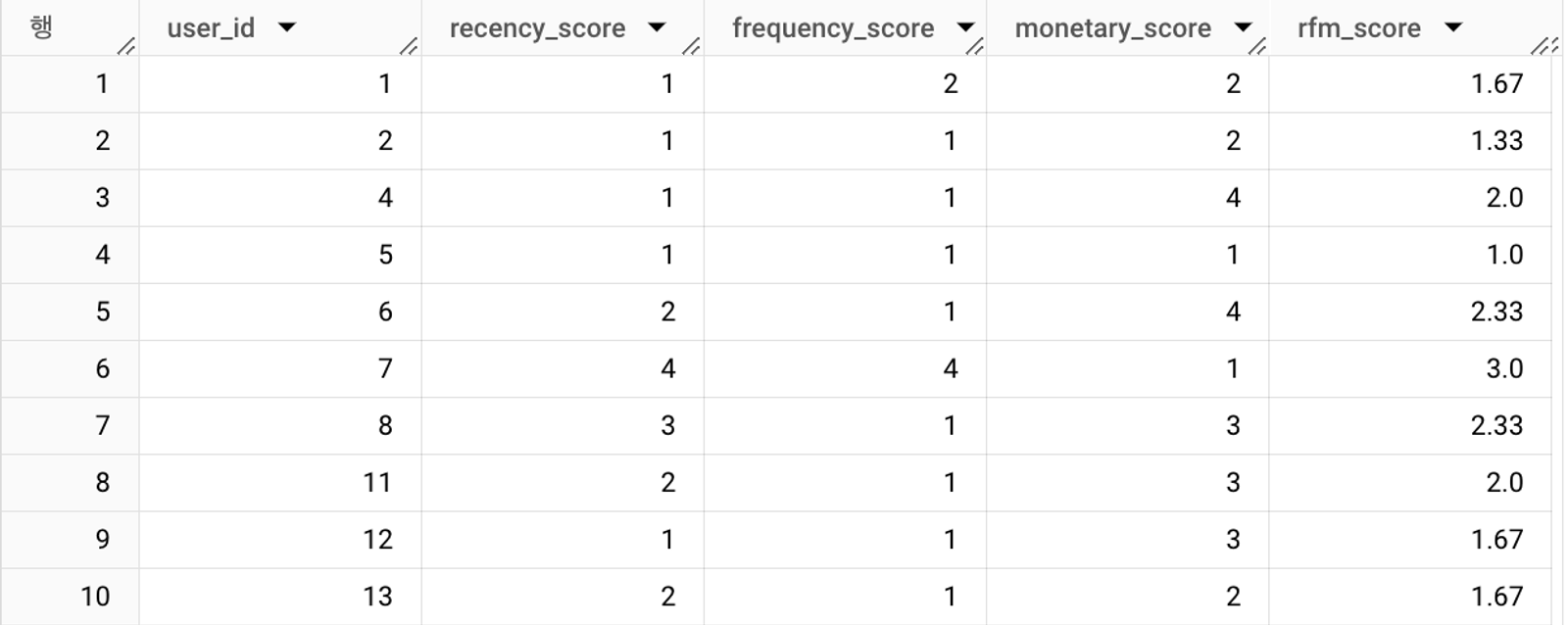
RFM 점수를 평균으로 구할 때 주의할 점
하지만 모든 RFM 속성이 같은 가중치를 가지지 않을 수 있다.
비즈니스의 특성에 따라 어떤 속성에 더 많은 가중치를 부여하여
RFM 점수를 계산하는 게 유의미할지 살펴보는 게 중요하다.
관련 아티클을 살펴봤을 때 패션/화장품을 판매하는 소매업에서는
매달 제품을 검색하고 구매하는 고객은 Monetary보다 Recency와 Frequency 점수가 더 높은 경향이 있다고 한다.
따라서 M보다 R, F 점수에 더 많은 가중치를 부여하여 RFM 점수를 구하기로 결정하였다.
SELECT user_id
, recency_score
, frequency_score
, monetary_score
, ROUND((recency_score * 0.4 + frequency_score * 0.4 + monetary_score * 0.2), 2) AS weighted_rfm_score
FROM `the_look_preprocessed.rfm`
ORDER BY user_id
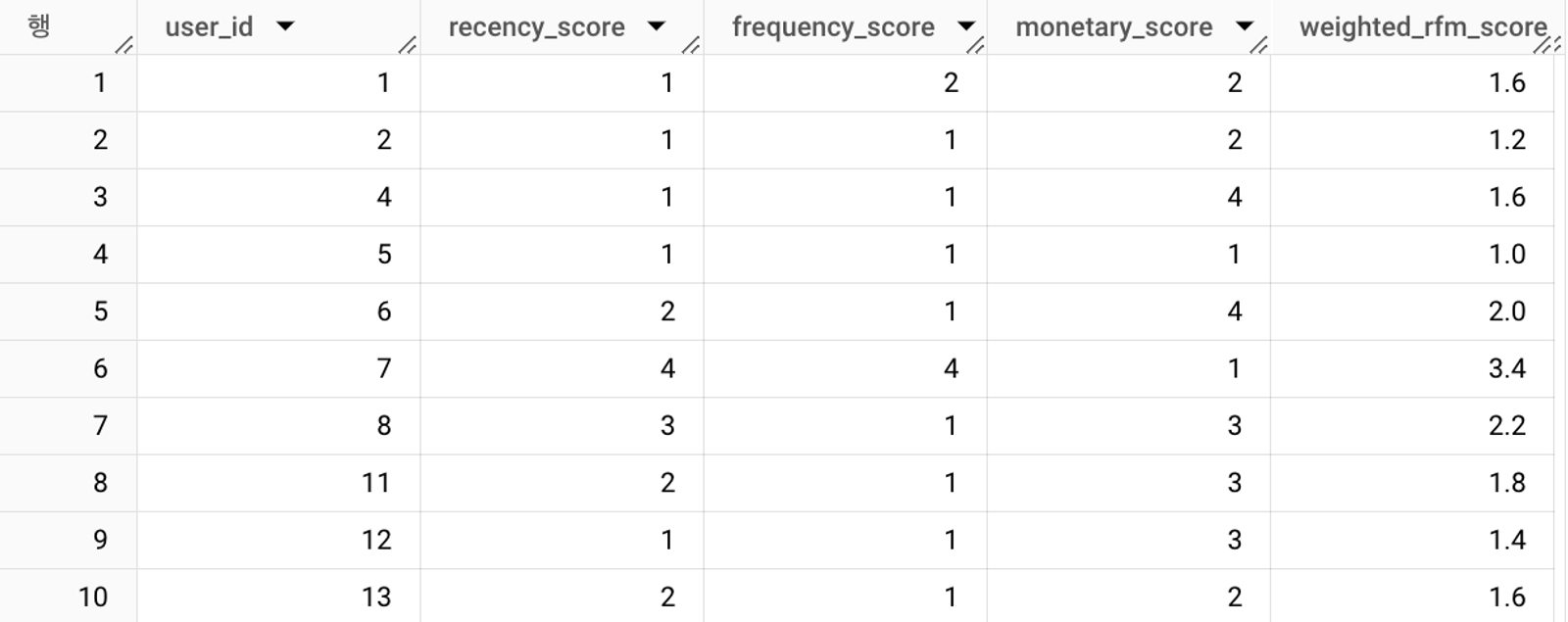
R에 40%, F에 40%, M에 20%의 가중치를 부여하여 weighted_rfm_score 열에 저장하였다.
태블로로 RFM Tree Map 구현하기
이렇게 구한 최종 RFM 점수에 따라 서로 다른 특성을 가지는 고객 세그먼트를 만들 수 있다.
세그먼트별 기준과 특징은 다양하게 잡아볼 수 있는데
필자는 태블로 위키의 RFM 세그먼트 분석을 참고하여 그 기준을 잡아보았다.
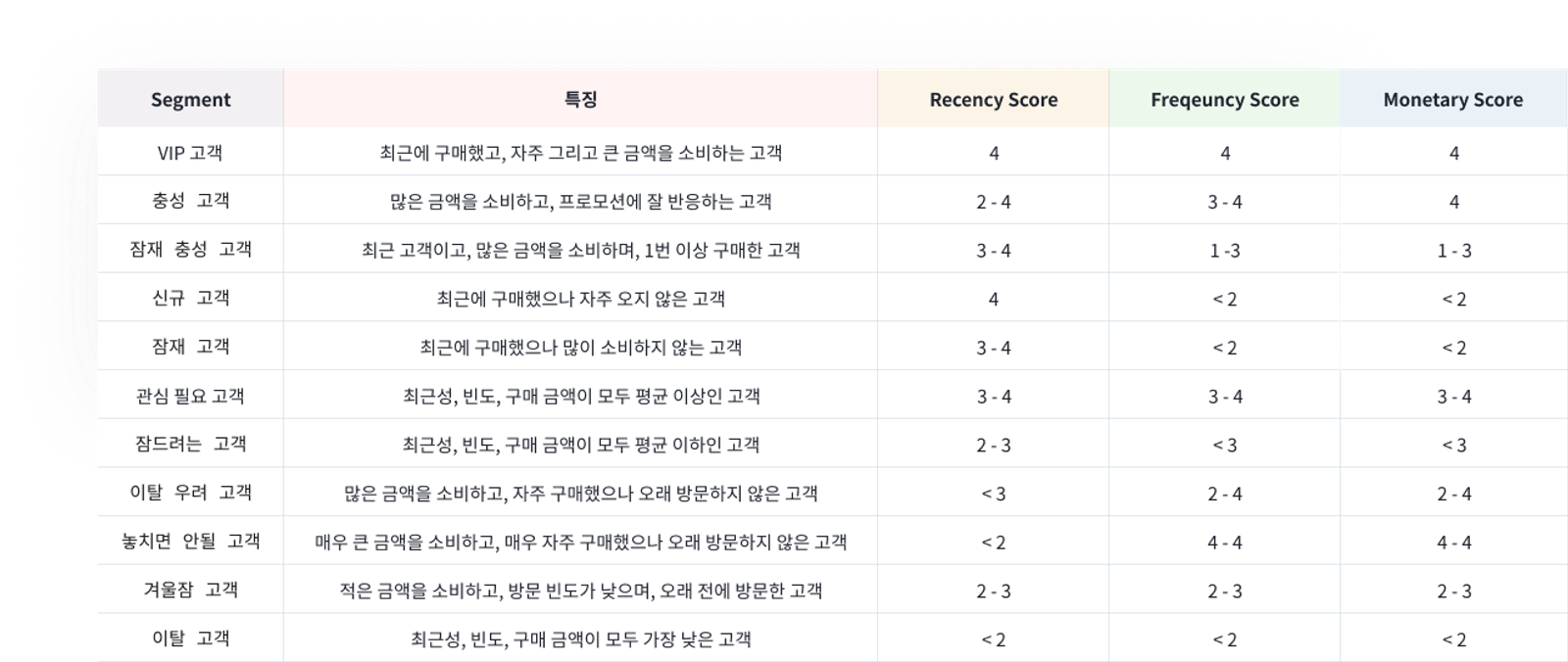
이는 SQL 쿼리로도 표현할 수 있으나 대부분 데이터 시각화나 BI 도구를 사용하여 간단한 분석을 수행한다.
필자의 경우 태블로로 Frequency 값을 측정값으로 두었고
전체 고객 중 각 세그먼트가 차지하는 비율을 RFM Tree Map을 만들어보았다.
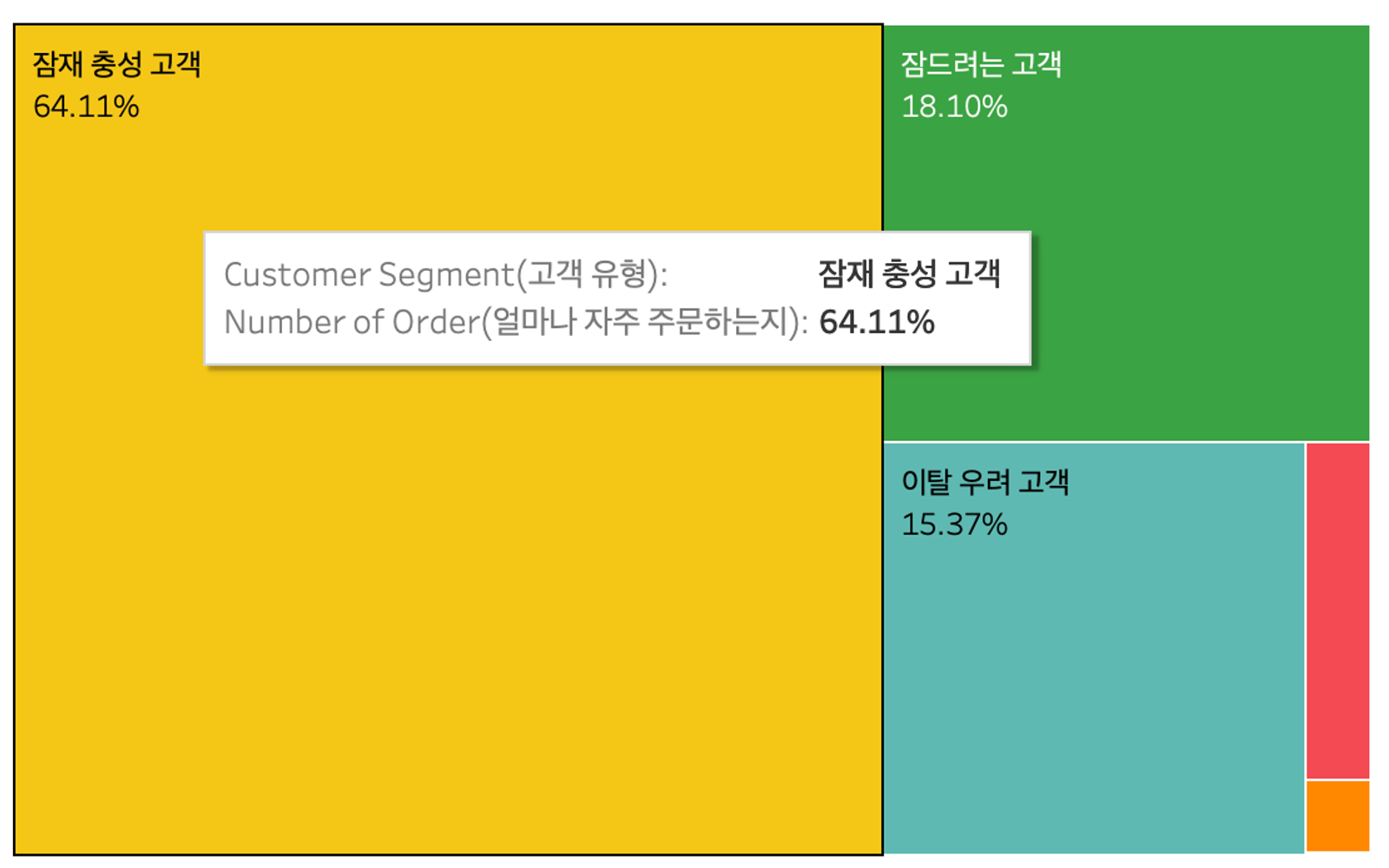
태블로로 가볍게 살펴본 결과,
최근 고객이고, 많은 금액을 소비하며 1번 이상 구매한 고객인
잠재 충성 고객 세그먼트가 64.11%로 가장 높은 비율을 차지하고 있다.
그 다음으로는 잠드려는 고객, 이탈 우려 고객 순으로 비율을 차지하고 있고
많은 금액을 소비하고 프로모션에 반응하는 '충성 고객'은
단 3개의 케이스만 나와서 트리맵에서는 제대로 보이지 않는다.
일단 1차로 해봤을 때 세그먼트별 기준에 맞지 않아 NULL인 값들도 상당 수 나와서
기준을 조금 바꾸어서 2차 분석을 진행해볼 수 있겠다.
더 생각해보기
이렇게 나온 결과를 바탕으로
각 세그먼트에 속하는 고객들의 특성을 분석하여
서비스에 충성도가 높은 사용자가 특별히 많이 방문한 페이지,
많이 구매한 상품이나 많이 사용한 기능을 찾아내어
이를 일반 사용자들이 많이 사용할 수 있도록 유도하는 등의 작업을 해볼 수 있겠다.
참고자료
'SQL' 카테고리의 다른 글
| [프로그래머스/MySQL] 대장균들의 자식의 수 구하기 (LEFT JOIN + COUNT 응용) (0) | 2025.04.06 |
|---|---|
| [TIL] Leetcode SQL 50 오답노트 - 이동평균 구할 때 쉬운 window 함수 (0) | 2025.03.05 |
| Streamlit과 BigQuery 연동 (with Google Cloud Platfrom) (1) | 2023.10.18 |
| PostgreSQL 기초 실습 및 개념 (0) | 2023.10.13 |
| MySQL - UK Commerce 데이터를 이용한 리포트 작성 (0) | 2023.10.12 |



