
본 게시물은 Stremalit에 BigQuery 데이터베이스에 연동하는 방법을 설명하는 글이다.
샘플 데이터로는 붓꽃 데이터, iris.csv 데이터를 활용했다.
BigQuery 데이터베이스 만들기
데이터세트 만들기
- Google Cloud 콘솔에서 BigQuery 페이지를 연다.
- 탐색기 패널에서 프로젝트 이름 옆 '점 세개 아이콘'을 클릭, 데이터 세트 만들기를 클릭한다.
- 데이터 세트 ID에 'project_dataset'를 입력한다.
- 데이터 위치 목록에서 US를 선택한다.
- 나머지 설정은 그대로 두고 데이터 세트 만들기를 클릭한다.
테이블에 데이터 로드
- 생성한 'project_dataset' 데이터 세트 옆에 있는 '점 세개 아이콘'을 클릭, 테이블 만들기를 클릭한다.
- 로컬에 있는 iris.csv를 업로드하기 때문에 테이블을 만들 소스는 '업로드'로 지정한다.
- 로컬에서 iris.csv를 선택, 파일 형식은 csv로 지정한다.
- 테이블에는 'iris'라는 이름을 입력한다.
- 나머지 설정은 그대로 두고 테이블 만들기를 클릭한다.
이러면 데이터 준비 완료!
BigQuery Client 라이브러리 설치
- 실행하고 있는 인스턴스의 외부 브라우저 창을 열고
아래의 명령문을 넣어 빅쿼리 클라이언트 라이브러리를 설치한다. - google-cloud-bigquery와 pandas-gbq 라이브러리 2가지를 설치한다.
pandas-gbq와의 비교 | BigQuery | Google Cloud
의견 보내기 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. pandas-gbq와의 비교 pandas-gbq 라이브러리에서는 쿼리를 실행하고 Pandas DataFrame을 BigQuery에 업로드할
cloud.google.com
Google-cloud-bigquery 설치
pip install --upgrade google-cloud-bigquery
Pandas-gbq 설치
pip install pandas-gbq
BigQuery API 활성화
- API 및 서비스 > 사용 설정된 API 및 서비스를 클릭한다.
- 검색창에 Bigquery를 검색한다.
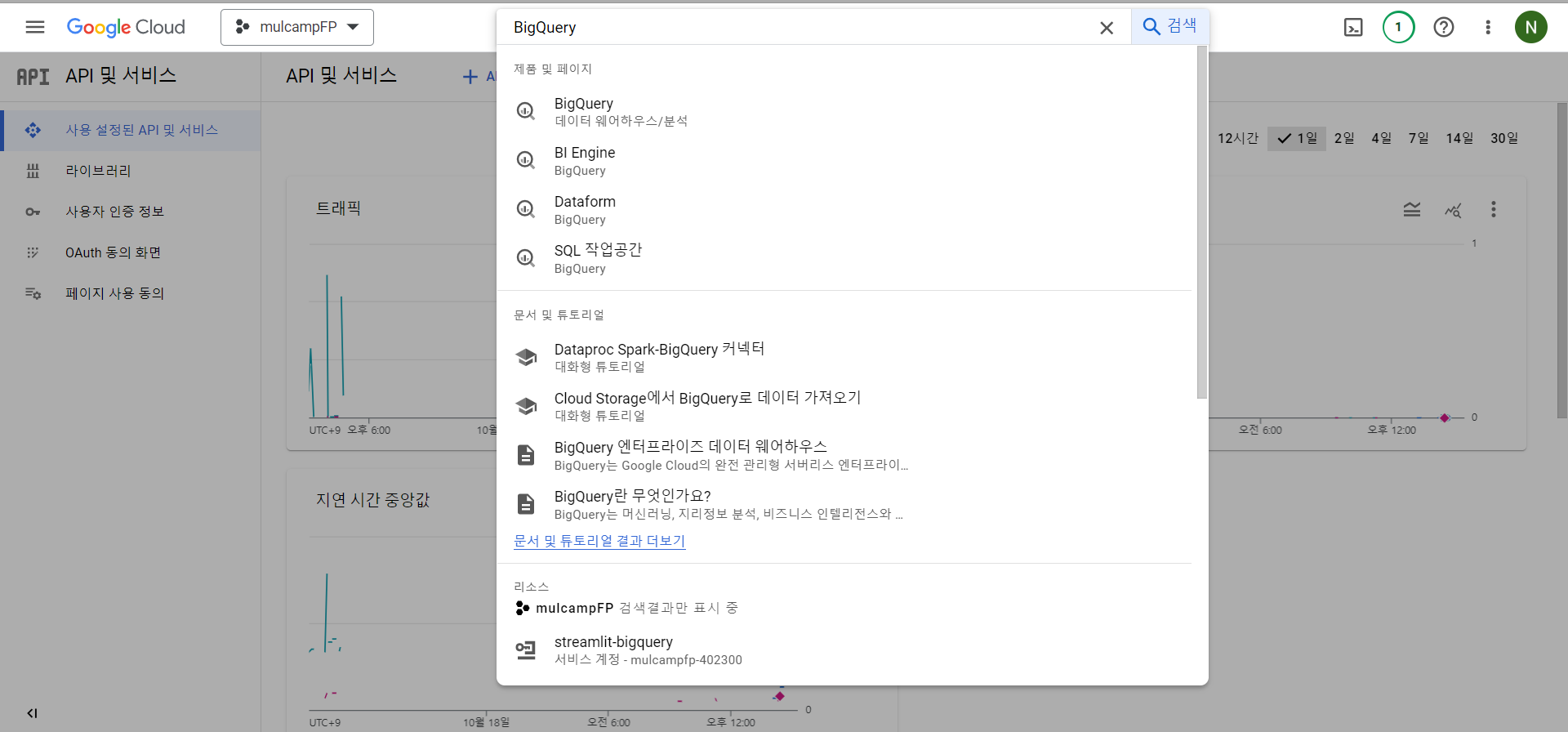
- BigQuery API의 사용 버튼을 클릭한다.
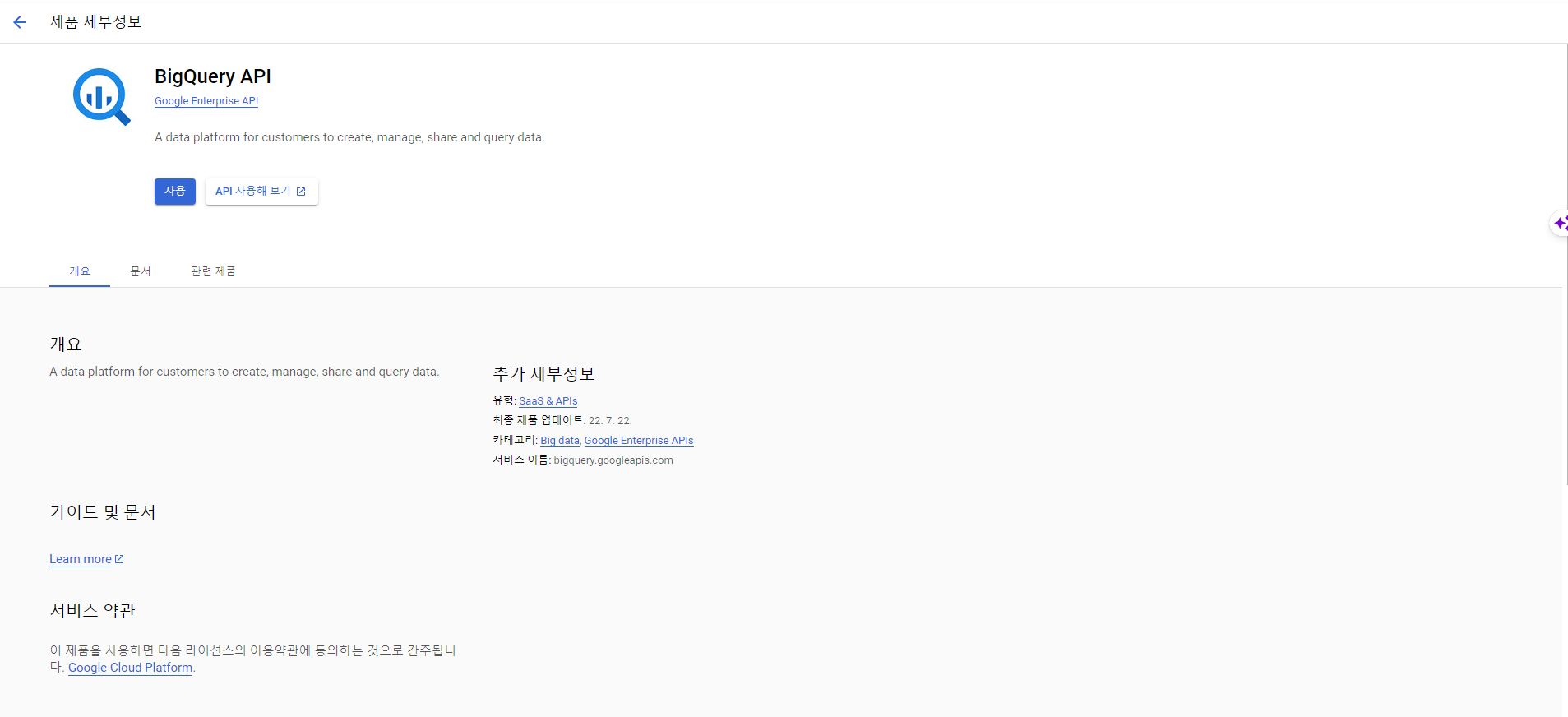
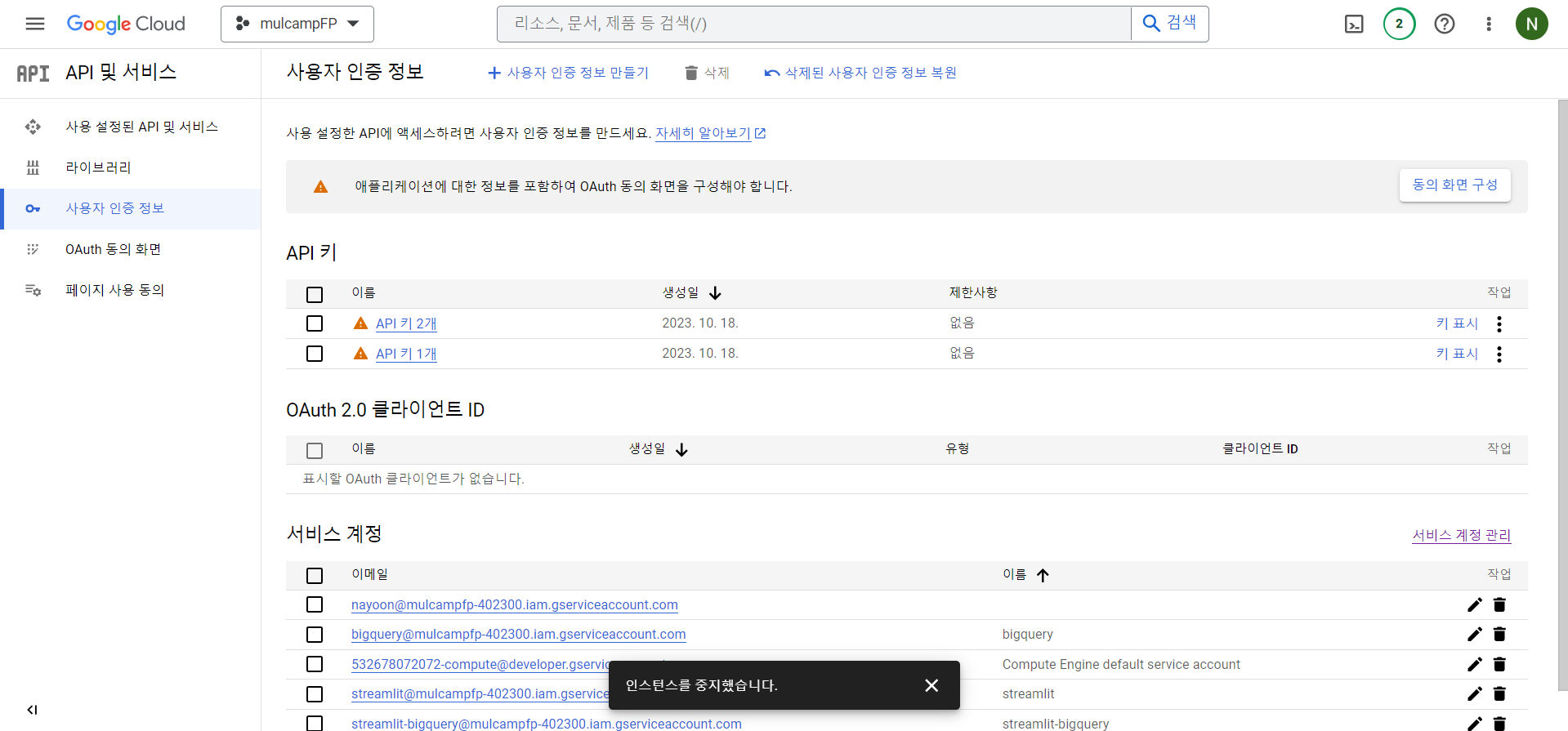
사용자 인증 정보 만들기
- API 및 서비스 > 사용자 인증 정보를 클릭한다.
- API 선택은 BigQuery API를 지정한다.
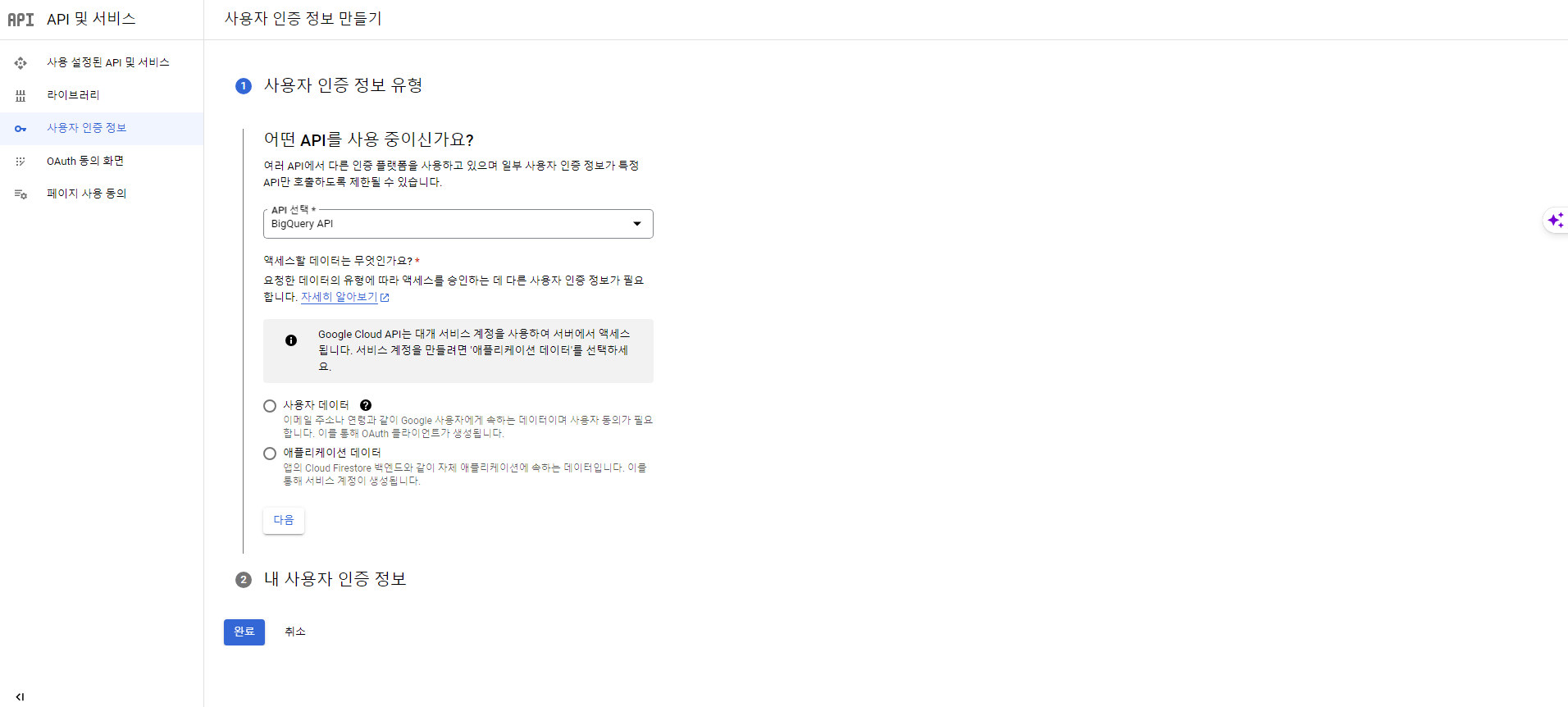
- 엑세스할 데이터는 애플리케이션 데이터로 지정한다.
- API를 하나 이상 사용할 예정이라고 체크한다.
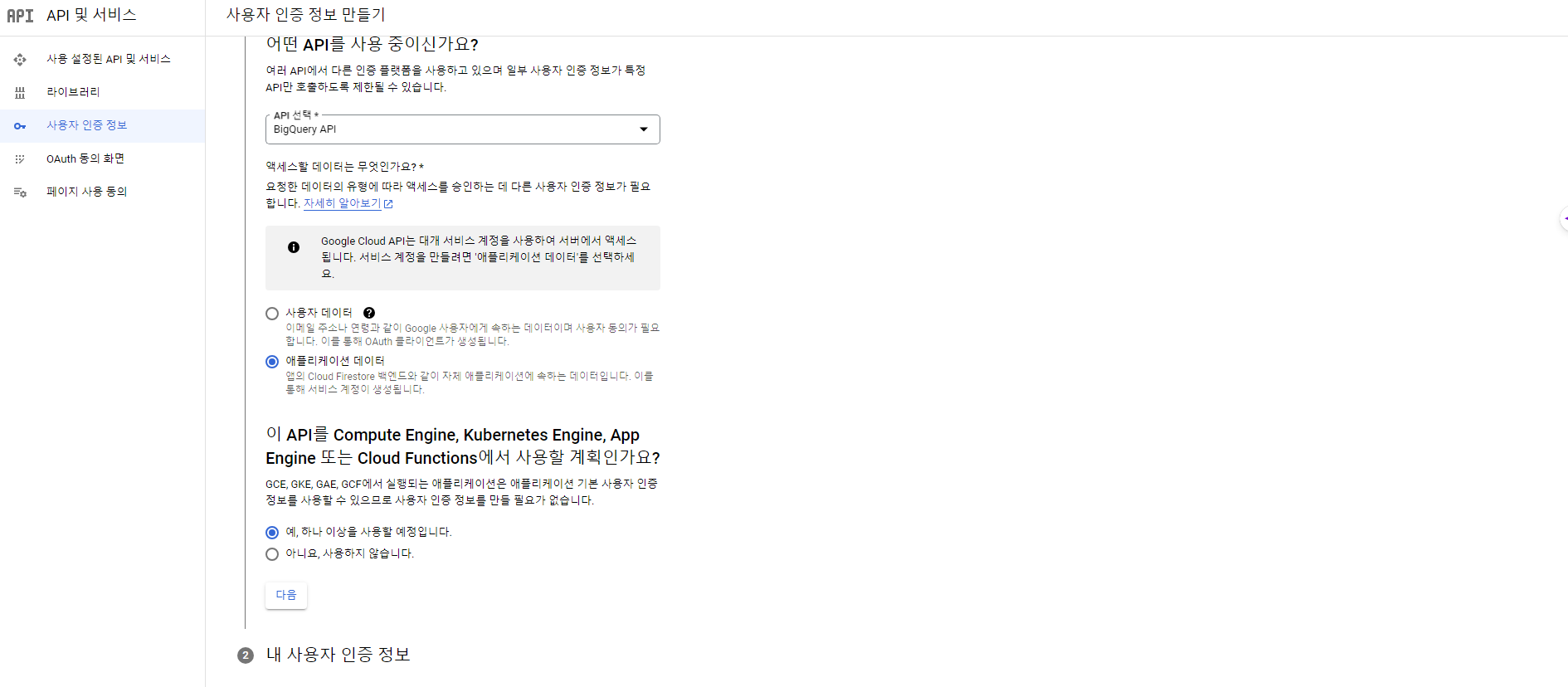
- 설정이 끝나면 '완료'를 클릭한다.
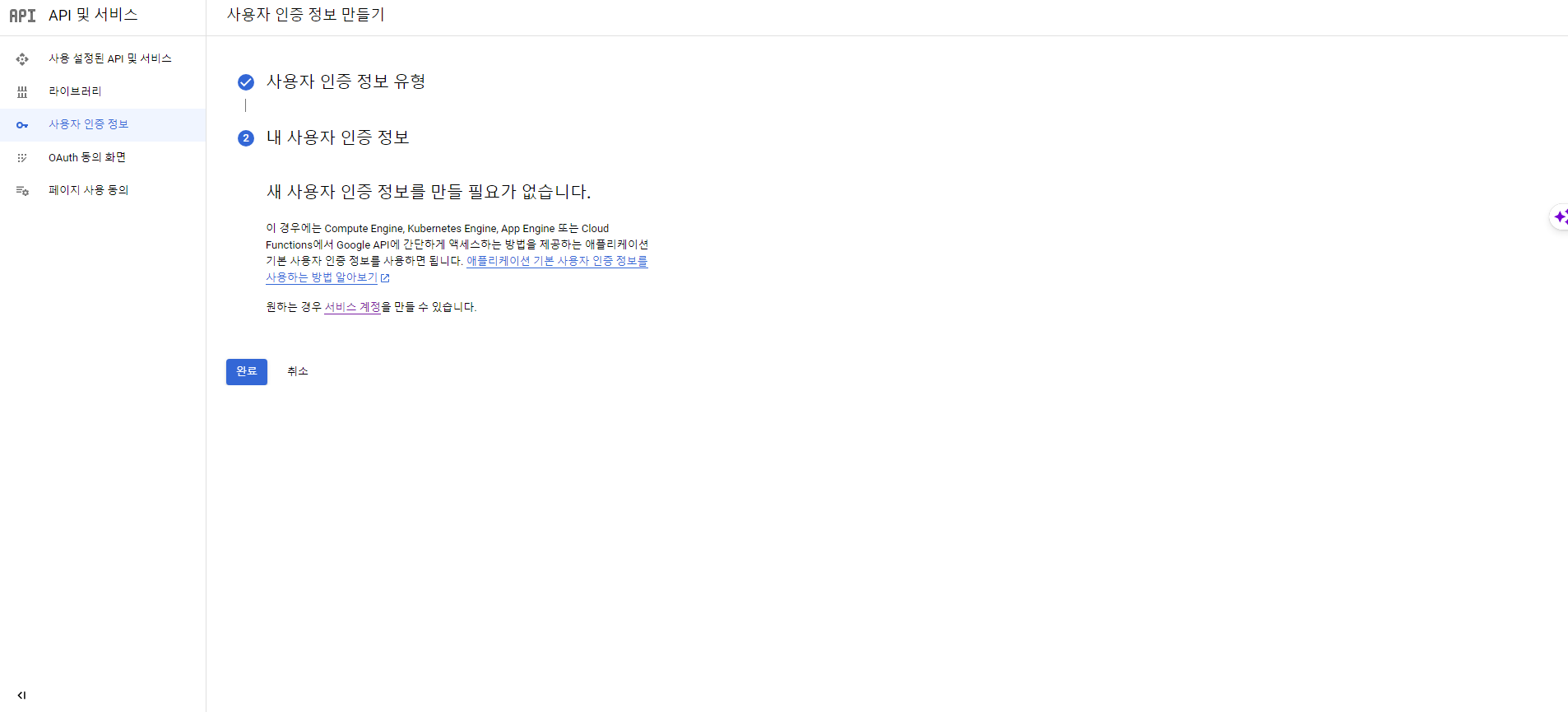
서비스 계정 및 키 파일 만들기
- SSH 브라우저 창을 열어 아래의 명령어를 입력해 서비스 계정 정보를 확인한다.
$ gcloud auth list
- IAM 및 관리자 > 서비스계정 화면에서 서비스 계정 만들기를 클릭한다.
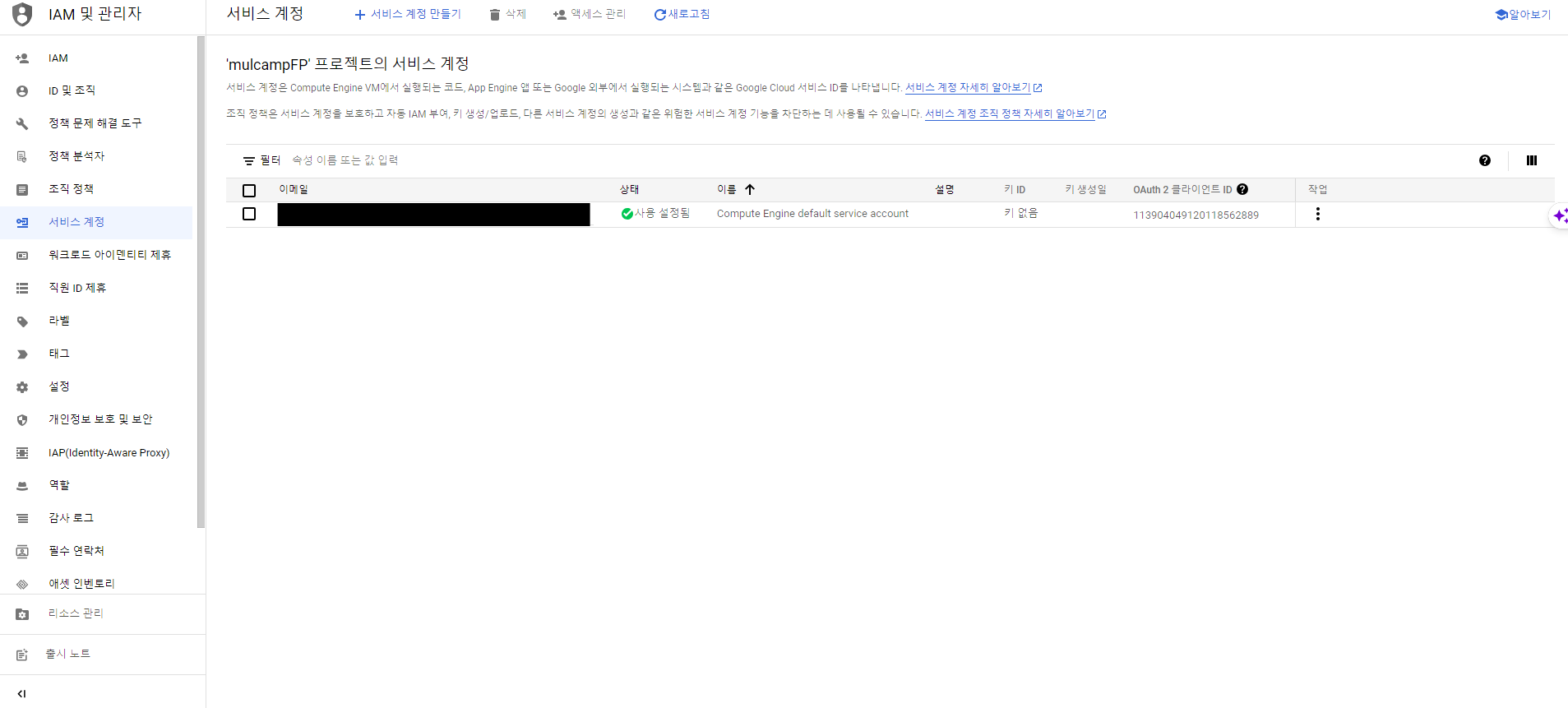
- 서비스 계정 ID는 'streamlit-bigquery'로 지정한다.
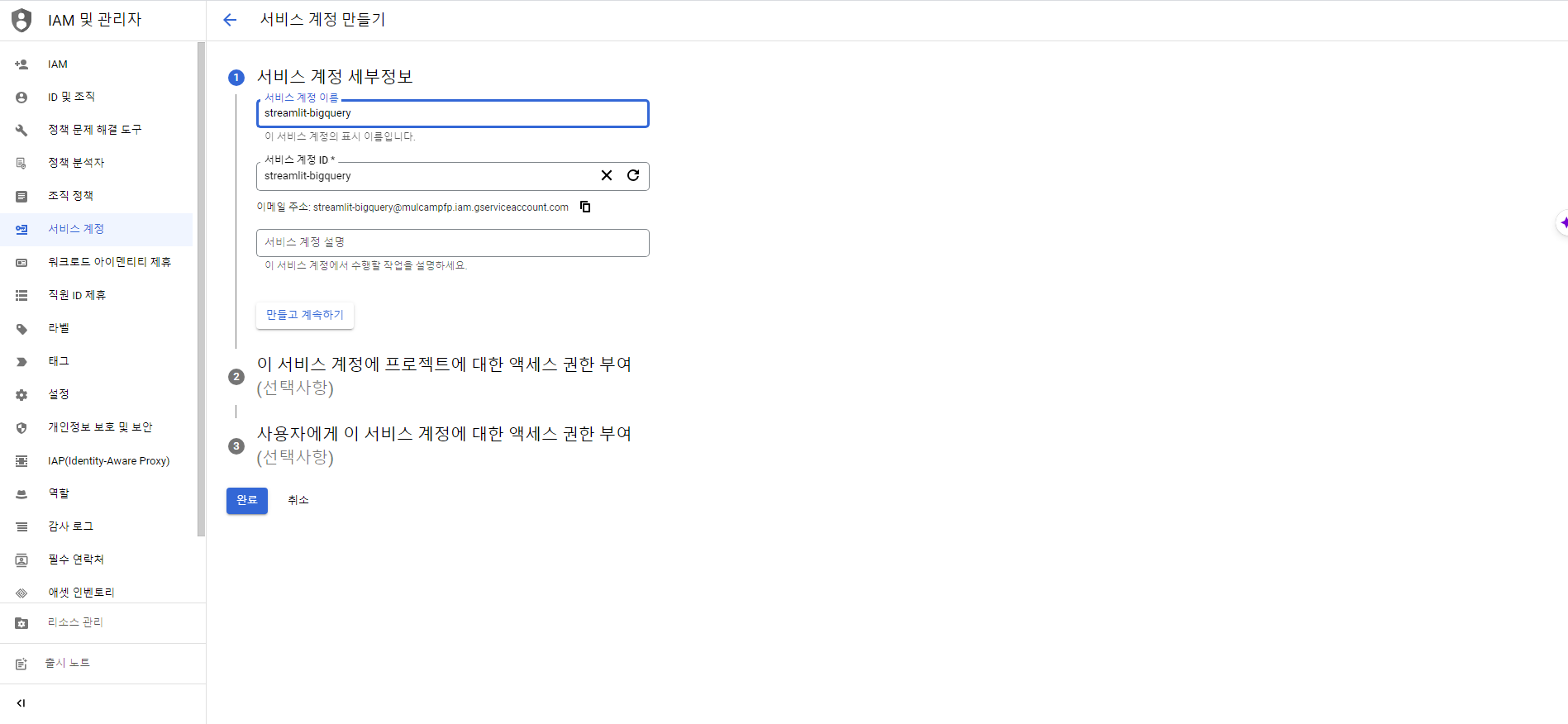
- 엑세스 권한 부여에서 역할은 소유자로 지정한다.
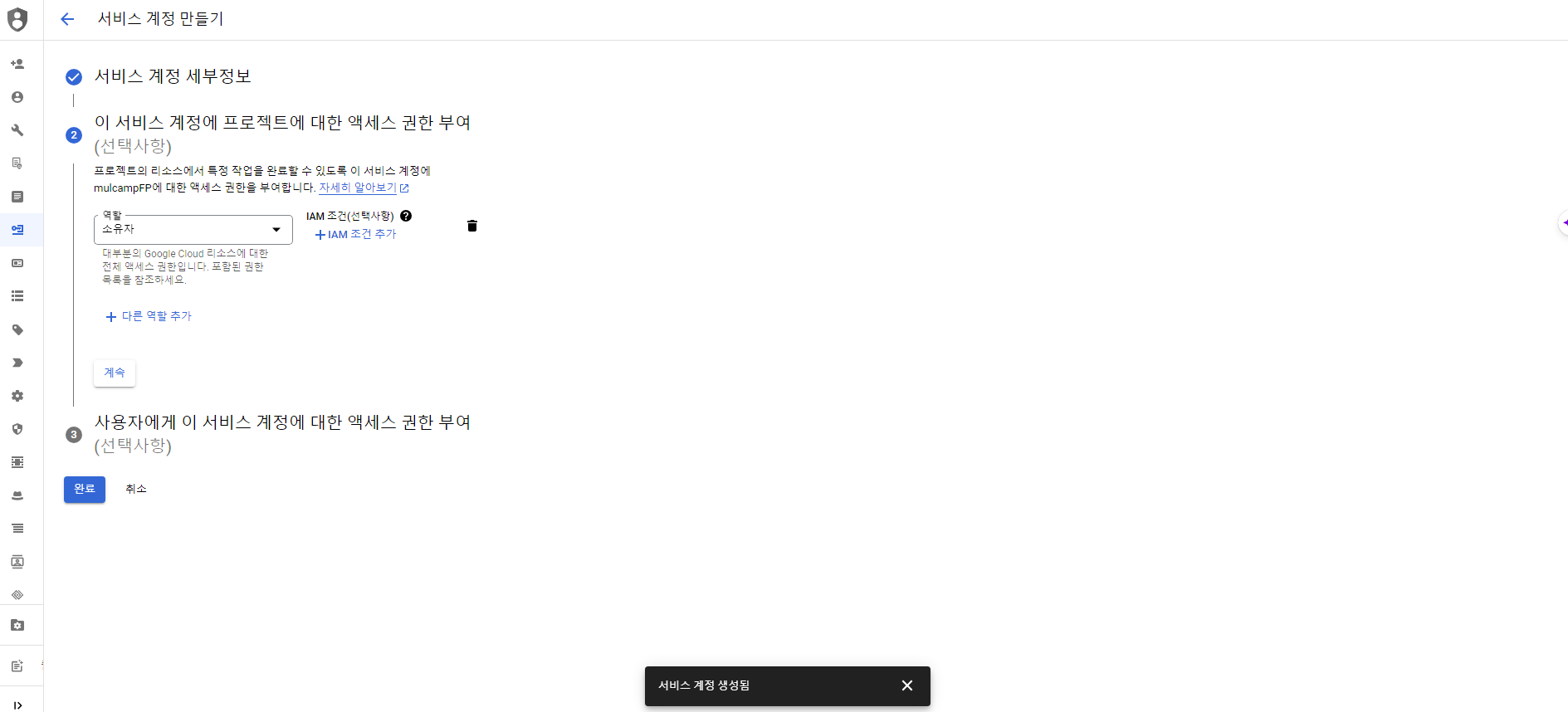
- 완료 버튼을 클릭한다.
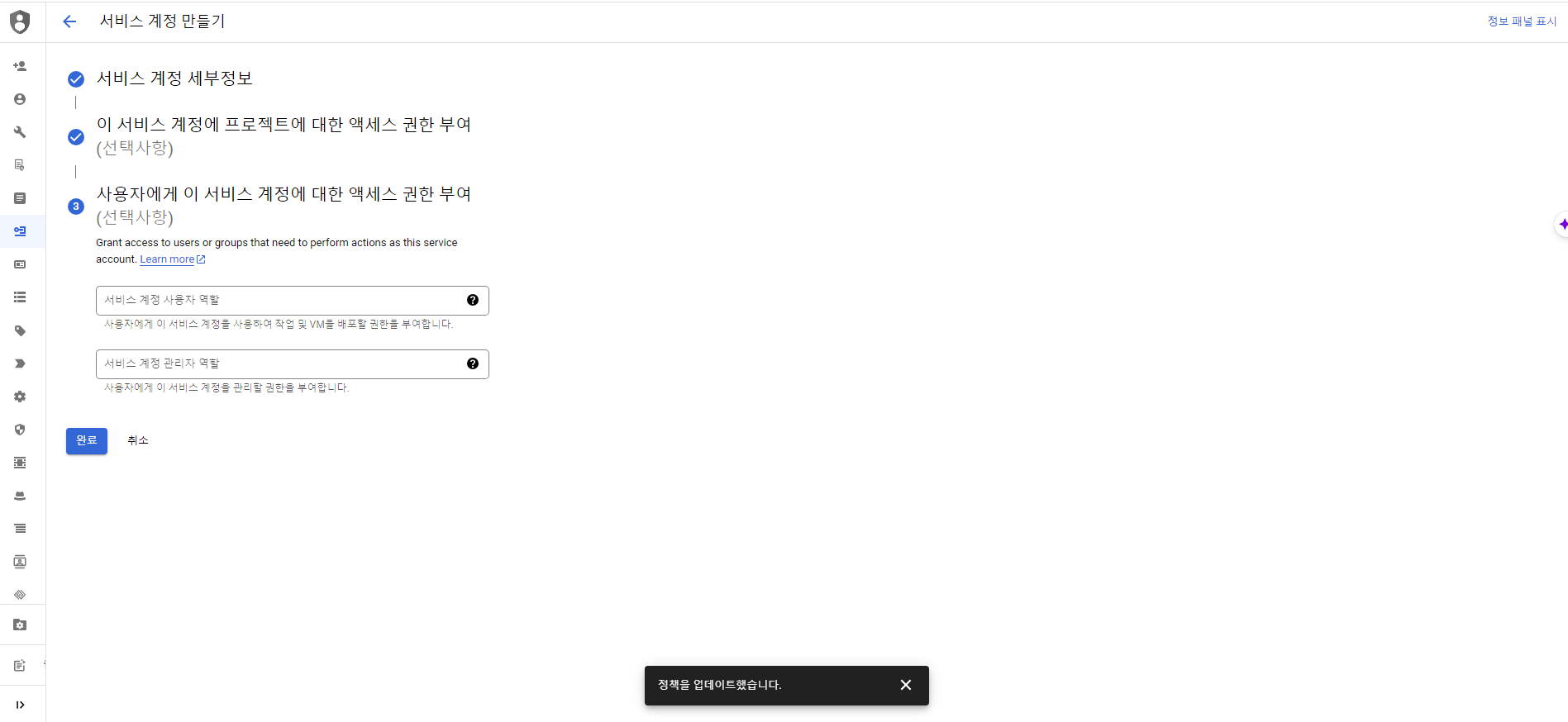
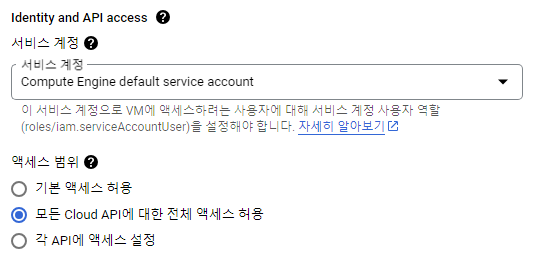
Compute Engine API 및 ID 관리
- Computer Engine의 VM 인스턴스로 이동, 현재 실행하고 있는 인스턴스 이름을 클릭한다.
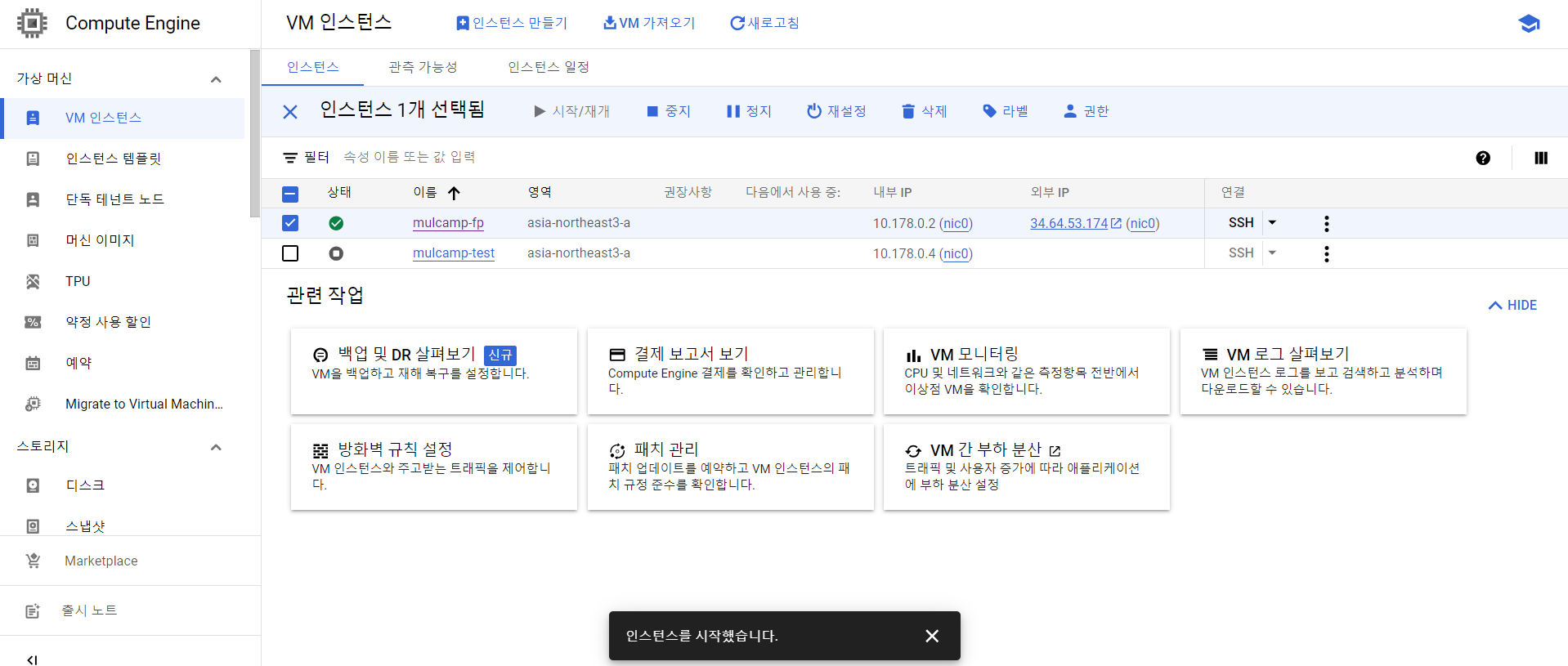
- 인스턴스 이름 옆의 수정을 클릭한다.
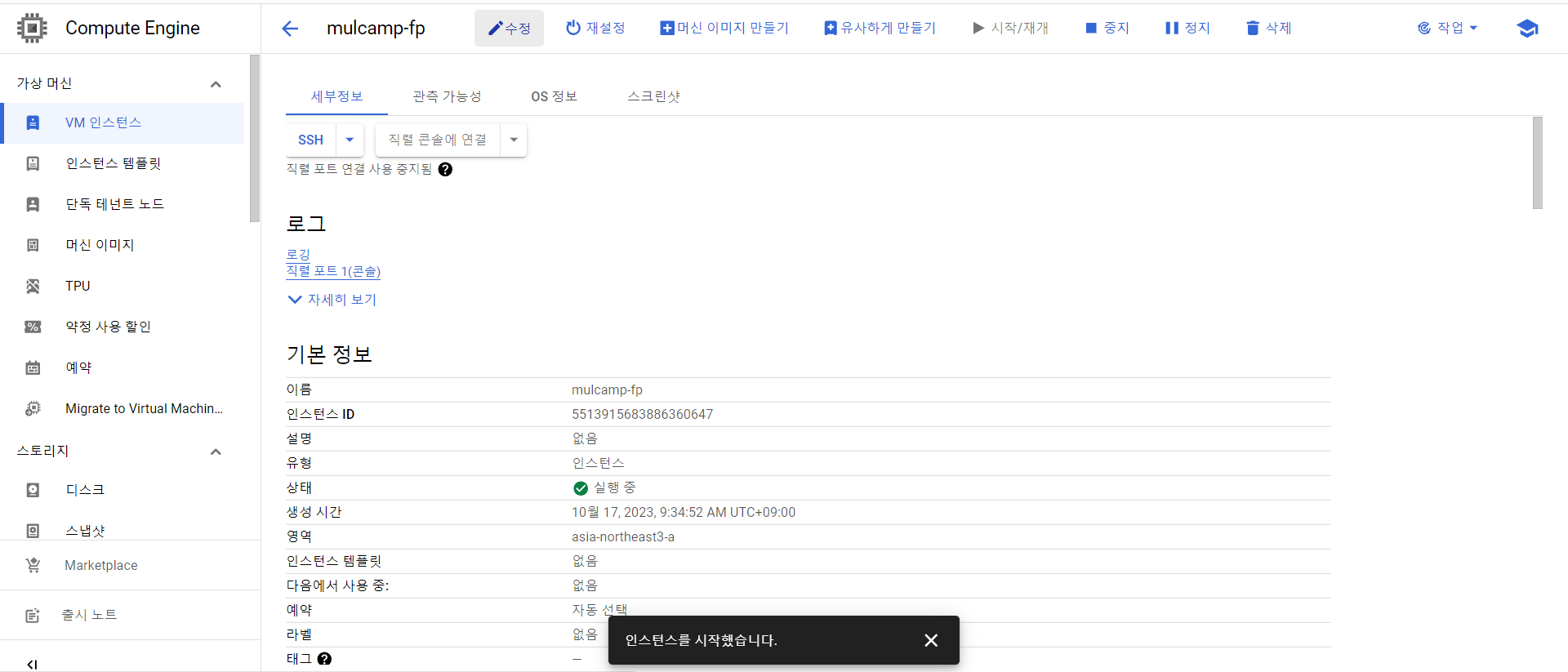
- Identity and API access 서비스 계정을 모든 Cloud API에 대한 전체 엑세스 허용으로 변경한다.
Sample Code 작성 및 수정
- 다시 브라우저 창을 열고 main.py 파일을 만든다.
vi main.py
- 수정 키로 전환 후 아래의 샘플 코드를 넣는다.
import streamlit as st
import pandas as pd
from google.auth import compute_engine
from google.cloud import bigquery
credentials = compute_engine.Credentials(
service_account_email='YOUR_EMAIL')
client = bigquery.Client(
project='YOUR_PROJECT_ID',
credentials=credentials)
# Perform query.
# Uses st.cache_data to only rerun when the query changes or after 10 min.
@st.cache_data(ttl=600)
def run_query():
sql = """
SELECT * FROM `mulcampfp-402300.project_dataset.iris` LIMIT 1000
"""
project_id = 'YOUR_PROJECT_ID'
df = pd.read_gbq(sql, project_id = project_id, dialect='standard')
st.write(df)
st.title("The query data 가져오기")
def main():
st.title("Streamlit Iris Data Visualization")
run_query()
st.write("""
## Explore the Iris dataset
Use the controls below to explore different visualizations of the Iris dataset.
""")
if __name__ == '__main__':
main()
- service_account_email은 브라우저 창에서 아래의 명령어를 입력해 나오는 acoount 정보를 참고한다.
$ gcloud auth list
- project는 project_id로 Cloud 개요 - 프로젝트 정보에서 확인할 수 있다.
Streamlit 서버 실행
- 정보를 알맞게 수정하면 streamlit으로 서버를 실행한다.
streamlit run main.py
- 출력값에 나온 URL을 주소창에 복사해서 엔터를 치면 아래와 같이
샘플코드로 짠 내용이 streamlit으로 구현된 걸 확인할 수 있다.

'SQL' 카테고리의 다른 글
| [TIL] Leetcode SQL 50 오답노트 - 이동평균 구할 때 쉬운 window 함수 (0) | 2025.03.05 |
|---|---|
| RFM 고객 세분화 분석이란? + The look ecommerce 데이터로 SQL 구현, Tableau 시각화까지 (1) | 2024.03.22 |
| PostgreSQL 기초 실습 및 개념 (0) | 2023.10.13 |
| MySQL - UK Commerce 데이터를 이용한 리포트 작성 (0) | 2023.10.12 |
| MySQL - 식품 배송 데이터 분석 (2) | 2023.10.10 |



