
본 게시물은 구글 클라우드 플랫폼(GCP)를 사용해 Spark를 설치하는 방법을 작성한 글이다.
멀티캠퍼스 실습 때 진행하여 프로젝트 시작부터 진행하고자 한다.
1. GCP 가입
- (사이트 주소 : https://console.cloud.google.com/welcome?project=inbound-density-387306)
- 첫 가입할 시 무료로 제공하는 300$ 크레딧을 받아서 사용하도록 하자.
- 필자는 기존 계정으로 이용한 적이 있어 새로운 계정을 파서 가입하였다.
2. 프로젝트 시작
- 가입을 마친 후 Google Cloud 옆 'My First Project' 버튼을 누르면
새로운 프로젝트를 열 수 있는 창이 뜬다. - 아래의 화면처럼 새 프로젝트를 시작한다.
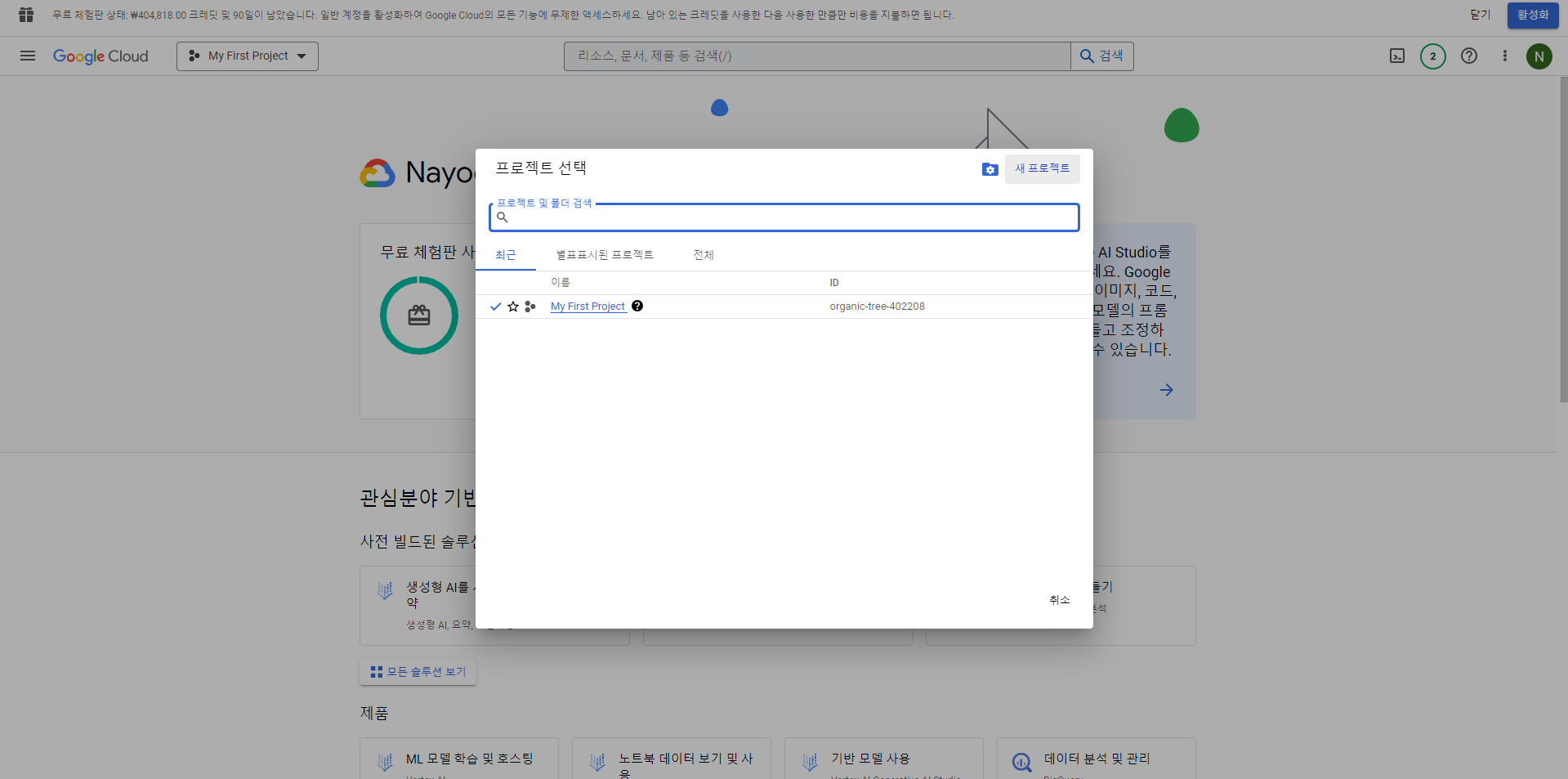
- 프로젝트명을 입력하고 만들기를 클릭한다.
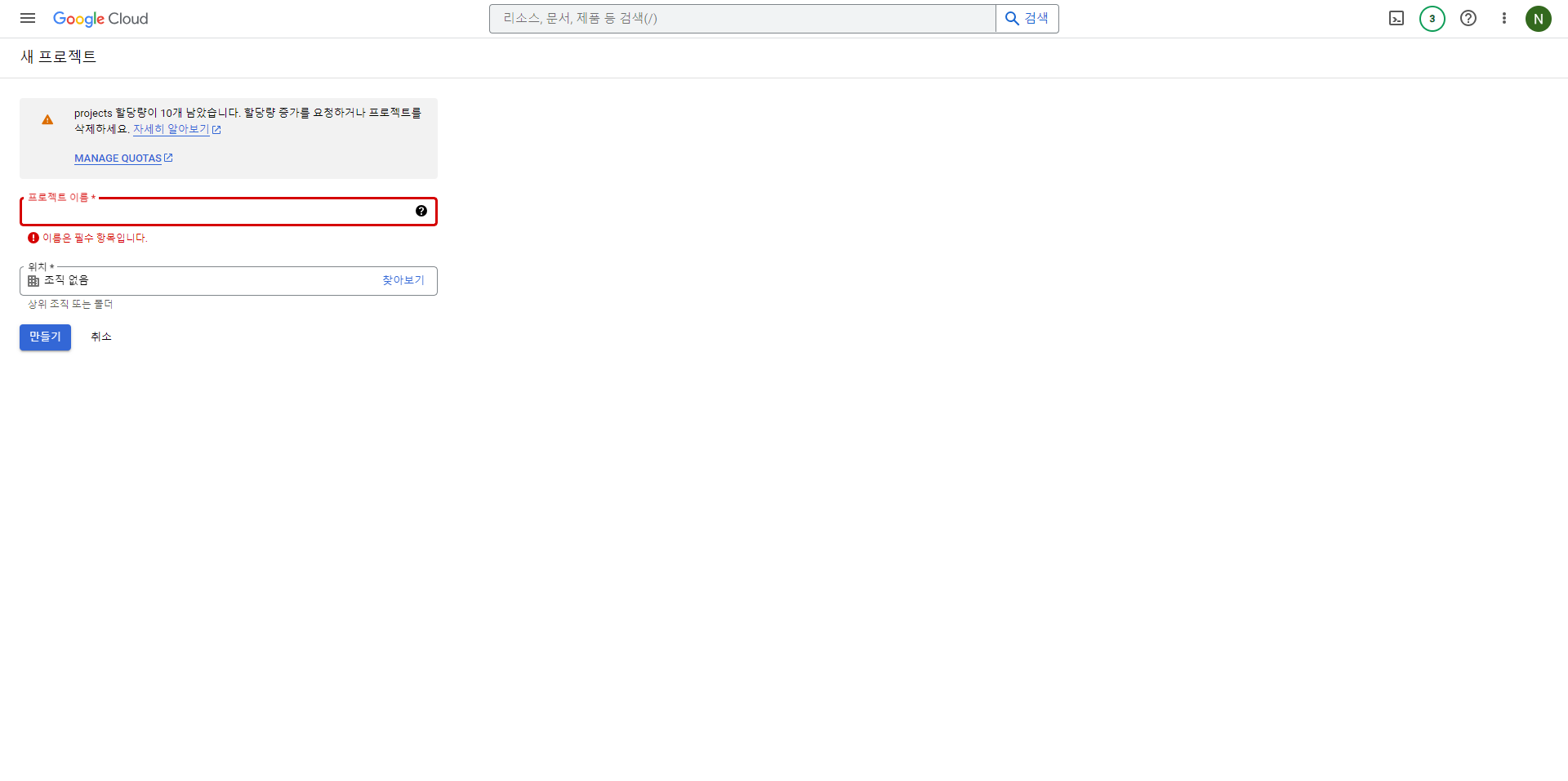
3. VM 시작하기
- 다시 첫 화면으로 돌아가 메뉴 - Computer Engine 를 클릭한다.
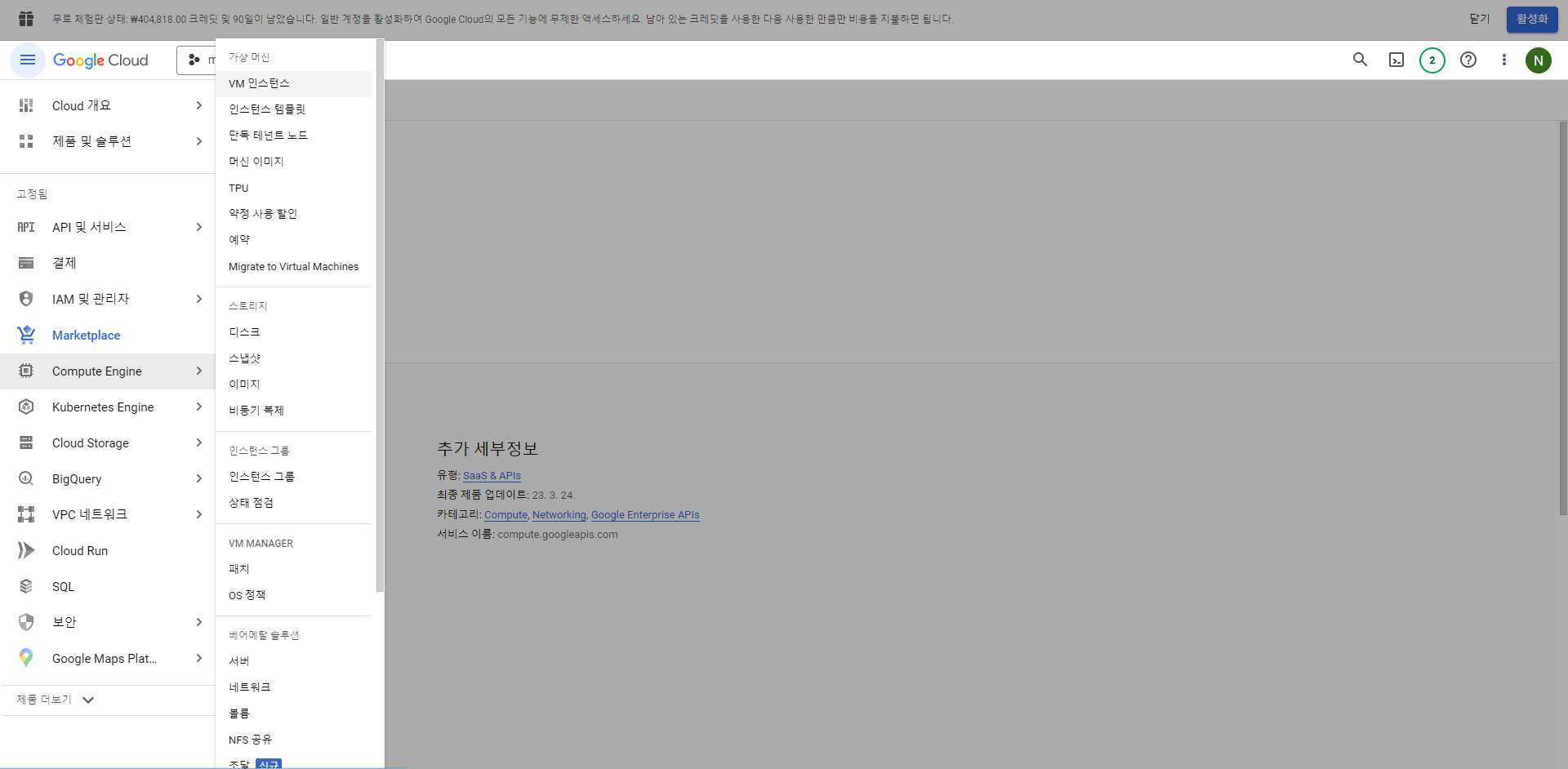
- Computer Engine API 하단의 사용버튼을 클릭해준다.
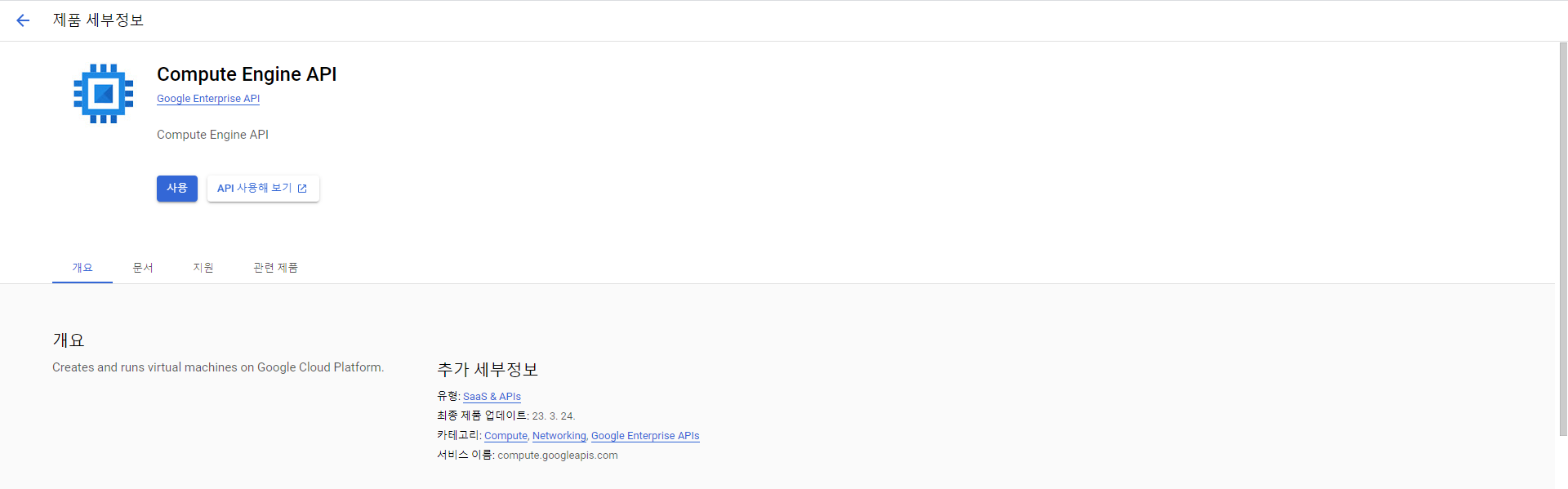
4. 인스턴스 만들기
- 로딩이 끝나면 아래와 같이 인스턴스를 만들 수 있는 환경이 마련된다.
- VM 인스턴스 옆의 '인스턴스 만들기'를 클릭한다.
- 인스턴스의 세부사항을 정할 수 있다.
- 필자는 아래와 같이 설정했다.
- 이름 : mulcamp-fp
- 리전 : 서울
- 머신 구성 : E2로 유지
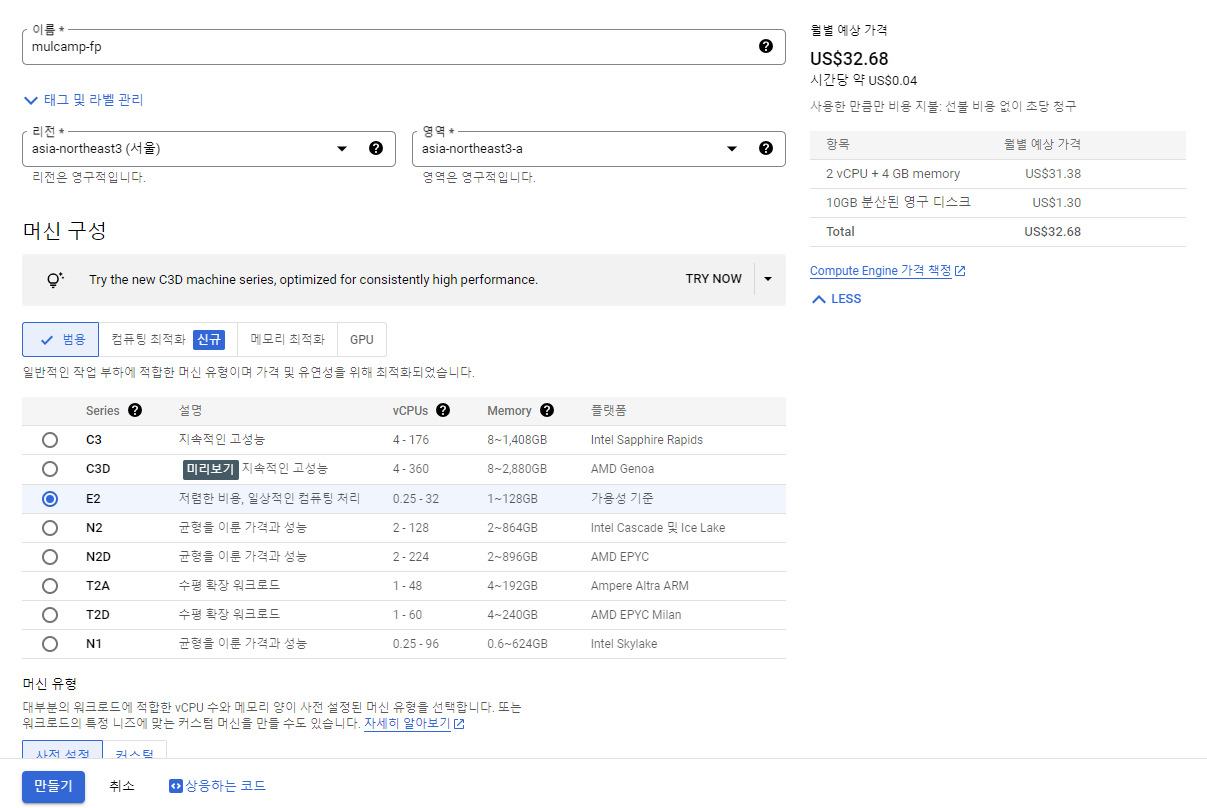
- 부팅 디스크는 Ubuntu로 변경했다.
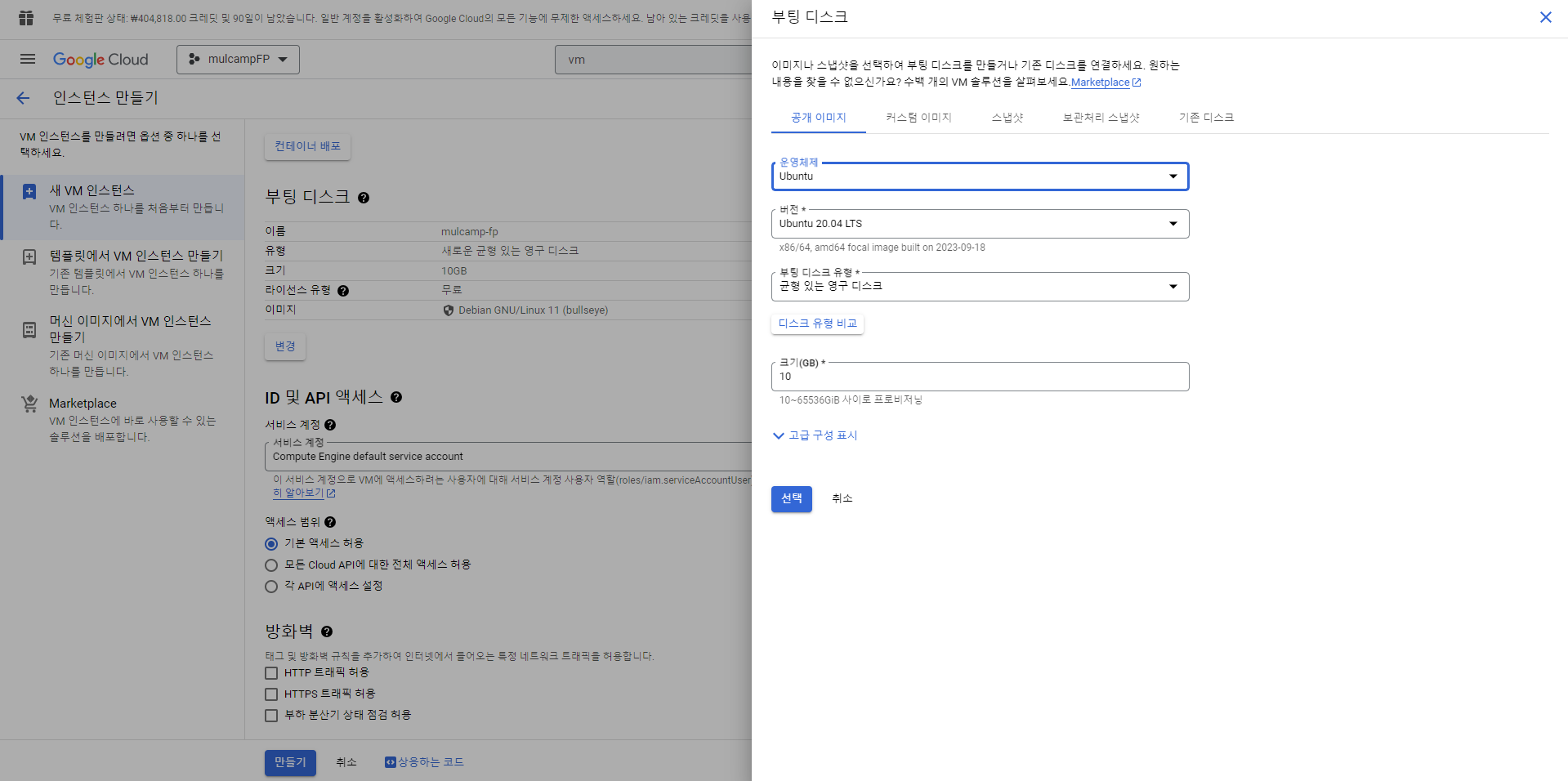
- 방화벽은 HTTP, HTTPS 트래픽 허용으로 두었다.
- 그외 설정은 기본 설정값을 유지하였다.
- 설정이 완료되면 만들기 버튼을 클릭한다.
5. 네트워크 보안 설정하기
- 프로젝트 배포를 진행하려면 병화벽을 열어줘야한다.
- 만든 인스턴스의 우측의 점 세개를 클릭, '네트워크 세부정보 보기'를 클릭한다.
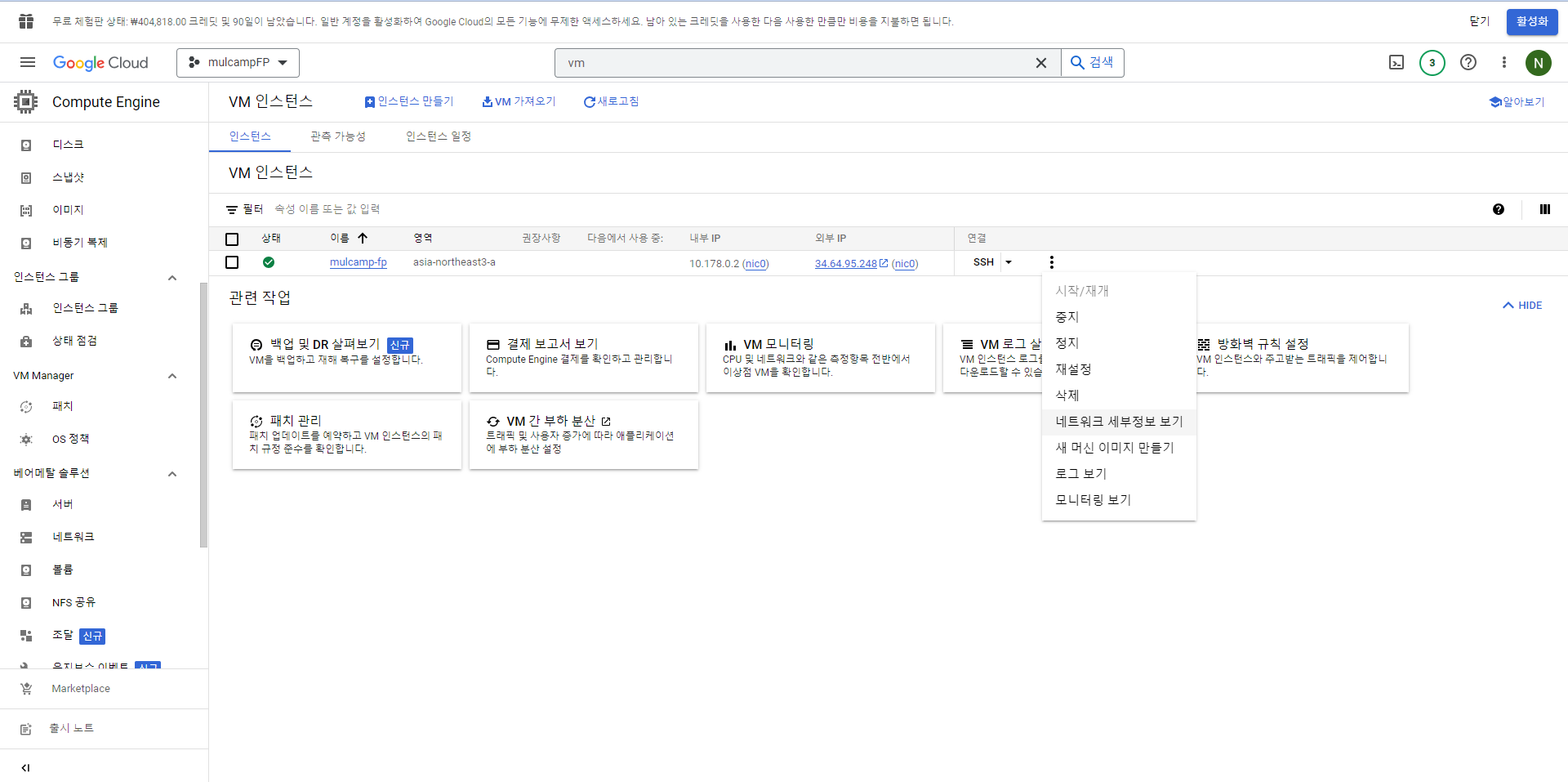
- 메뉴의 방화벽 - 방화벽 규칙 만들기 를 클릭한다.
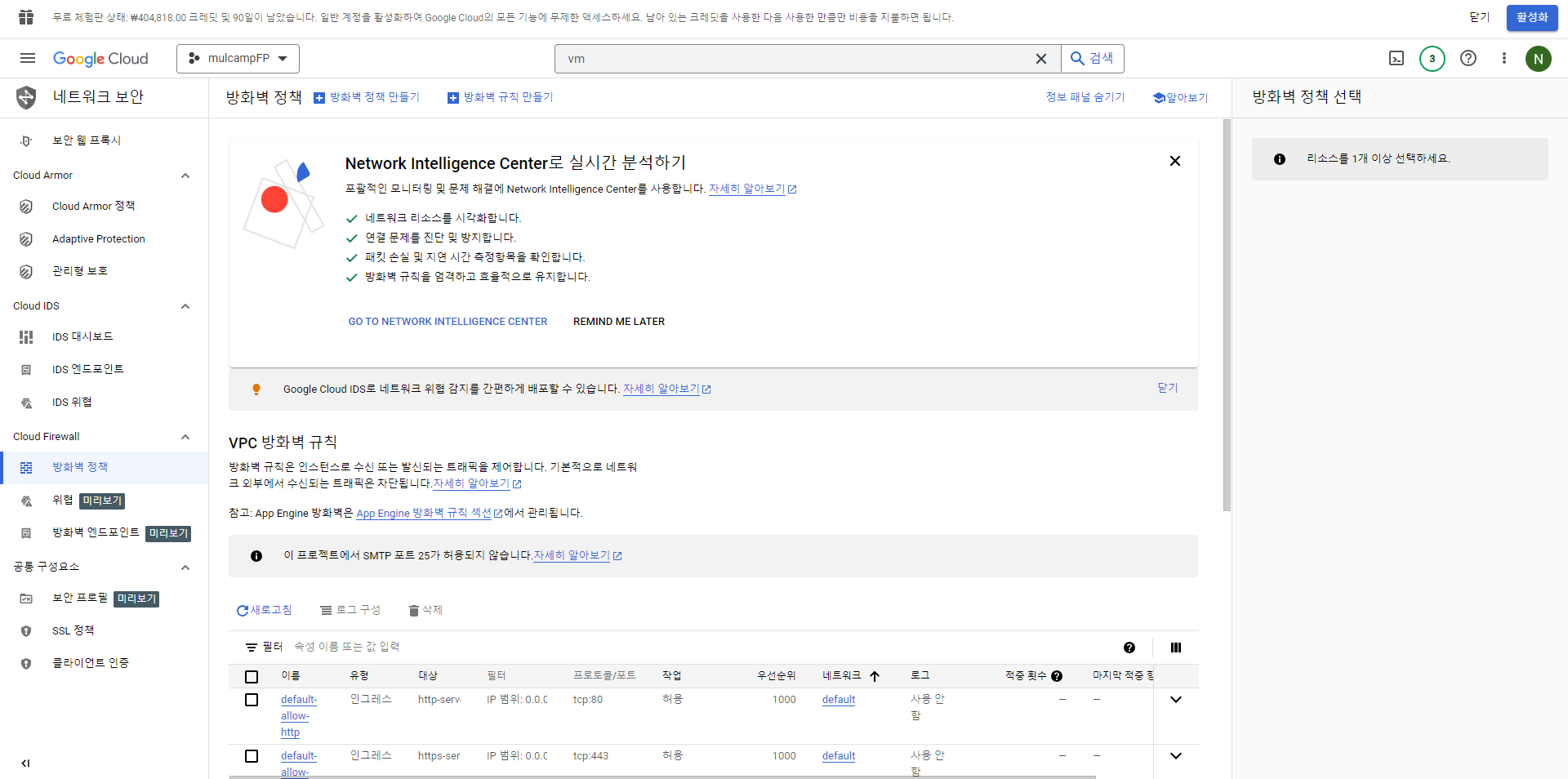
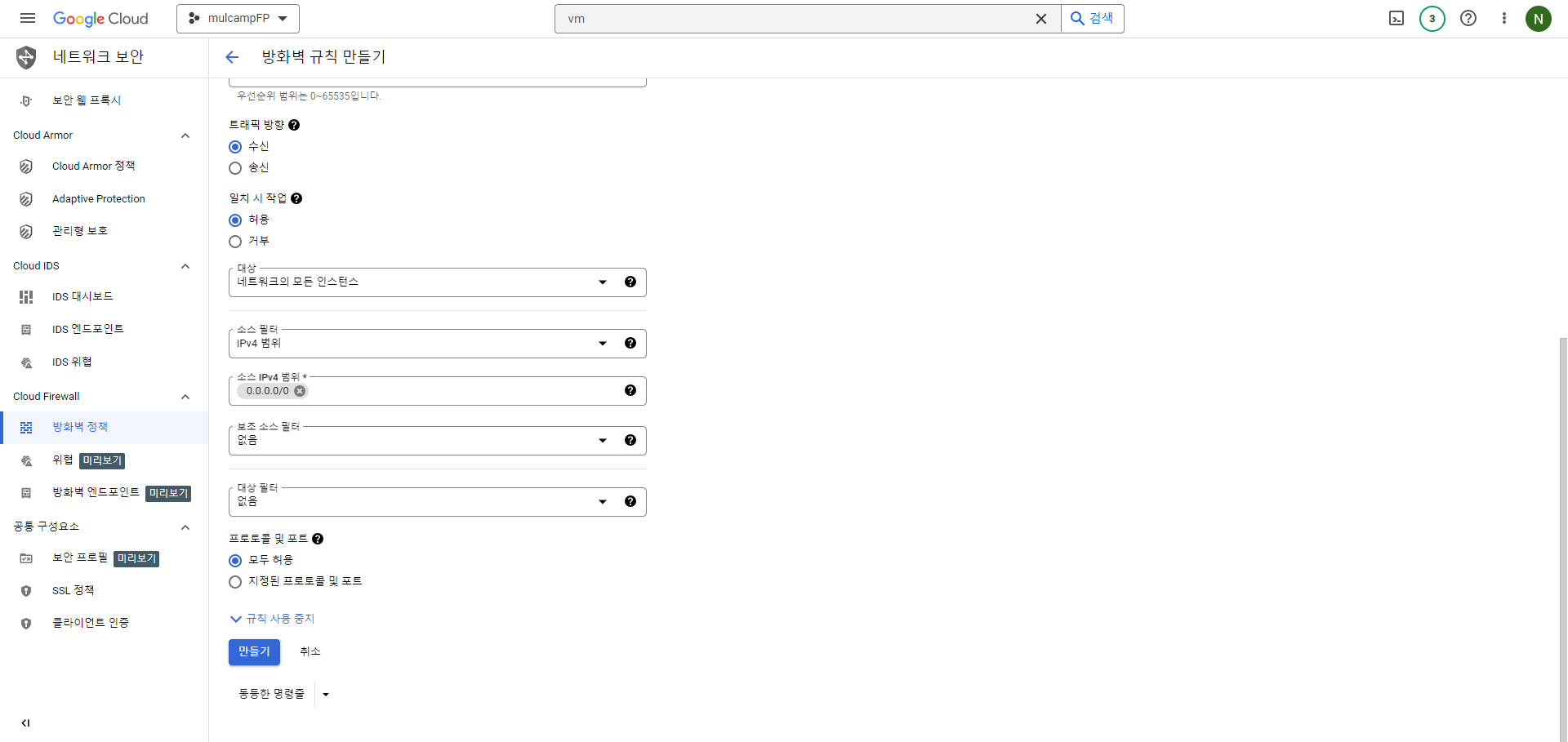
- 방화벽 규칙은 아래와 같이 지정했다.(그외 설정은 모두 기본값)
- 이름 : finalproject
- 대상 : 네트워크의 모든 인스턴스
- 소스 IPv4 범위 : 0.0.0.0/0
- 프로토콜 및 포트 : 모두 허용
6. 개발환경 설치
- 설치가 완료되면 왼쪽 메뉴바에서 Computer Engine을 클릭한다.
- 인스턴스의 SSH 버튼을 클릭, 브라우저 창에서 열기를 클릭한다.
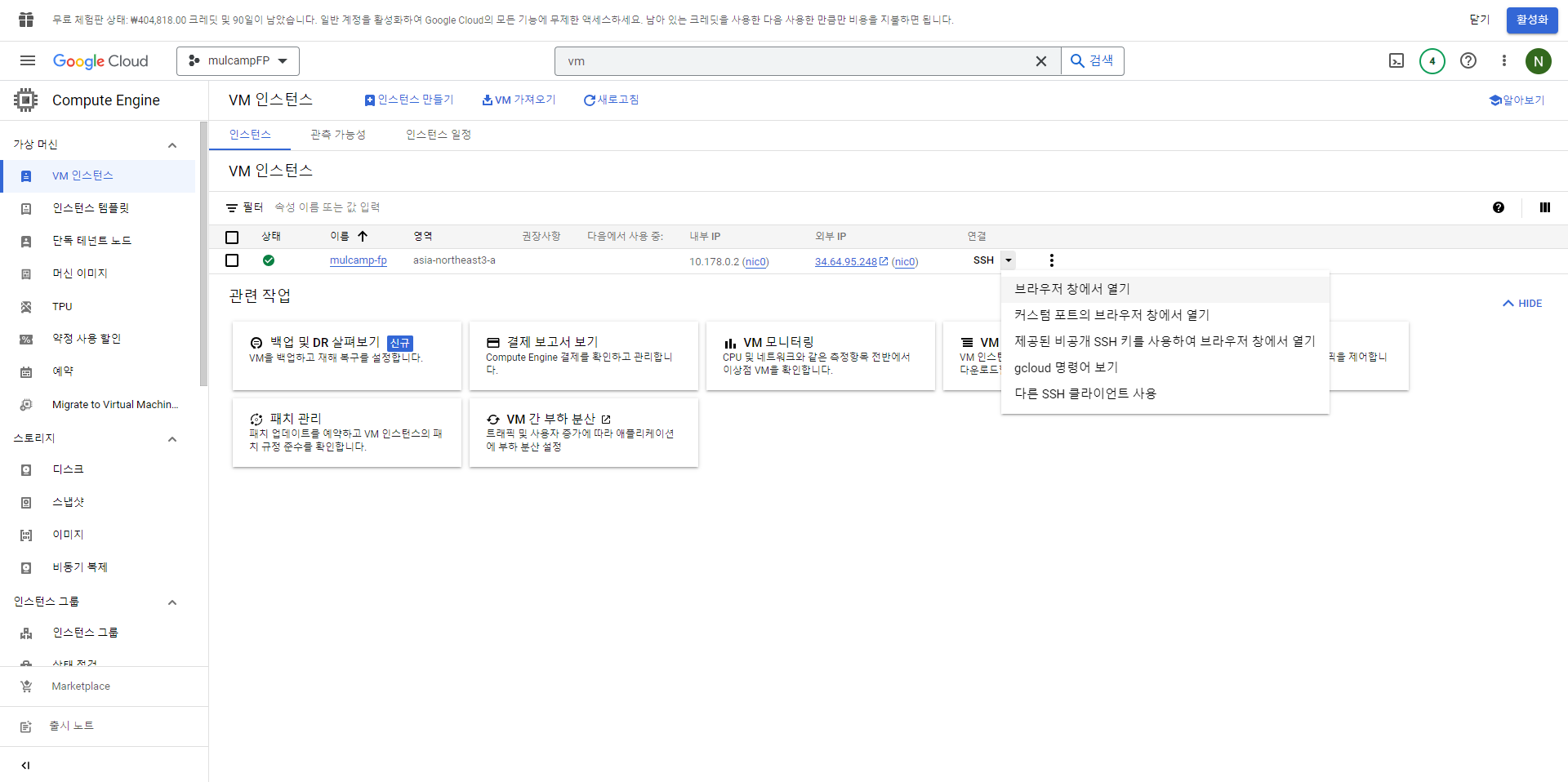
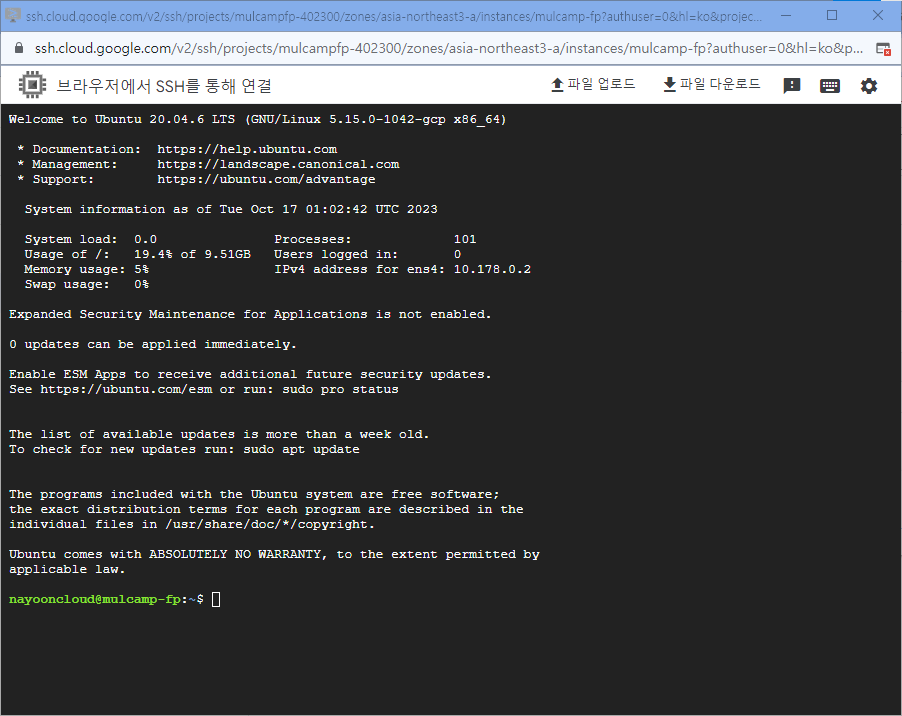
- 그러면 아래와 같은 화면이 나온다.
- 이곳 GCP를 통해서 이제 Spark를 위한 개발환경을 설정할 것이다.
7. miniconda 설치
- 먼저 경로는 opt 경로로 이동한다.
$ cd ../../opt
/opt$ pwd
아나콘다 설치를 위해 아래의 코드를 복사해 입력한다.
- (아나콘다 사이트 참고 : https://docs.conda.io/projects/miniconda/en/latest/)
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
- 아나콘다 설치가 완료되면 아래의 명령어를 실행한다.
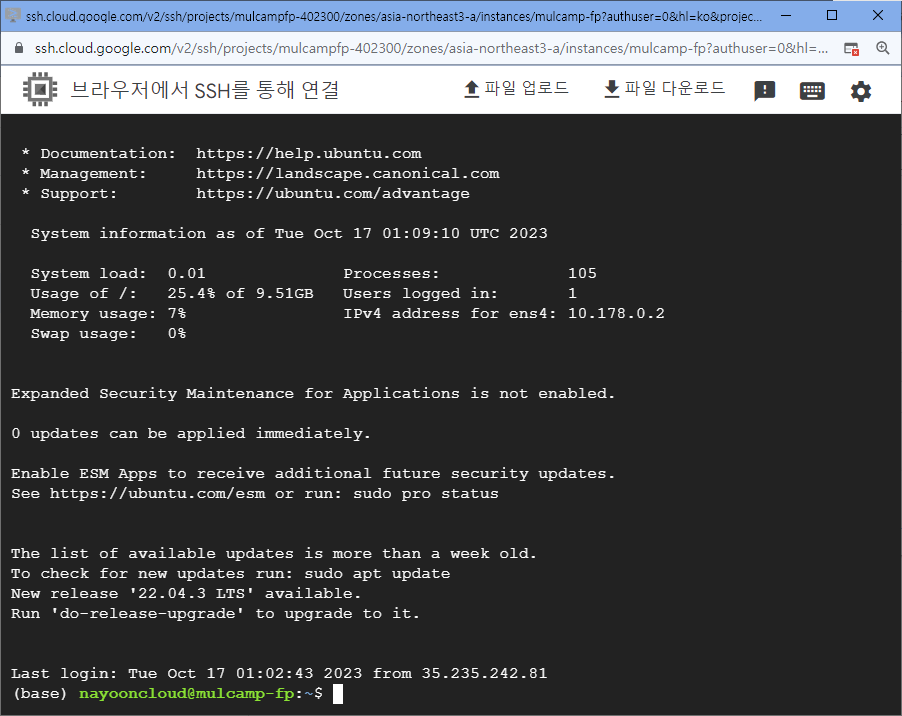
- 이후 브라우저 창을 닫고 다시 연다.
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zsh
- 다시 열 때 아래와 같이 (base)가 활성화 되면 miniconda가 정상적으로 설치된 것이다.
8. JAVA 설치
- 우선 다시 cd ../../opt/ 경로로 이동한다.
- 아래 2개의 명령문을 순차적으로 입력, JAVA를 설치한다.
(base) /opt$ sudo apt update
(base) /opt$ sudo apt install openjdk-8-jdk -y
- JAVA 환경변수 설정을 위해 vi ~/.bashrc 명령어를 실행하여 파일을 연다.
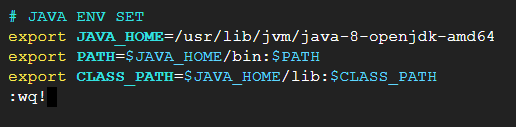
- 하단에 키보드 커서를 둔 채로 i 입력 (수정 키로 전환) 후 아래와 같이 코드를 추가한다.
# JAVA ENV SET
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
export CLASS_PATH=$JAVA_HOME/lib:$CLASS_PATH
- 이후 esc - ':wq!' 로 편집한 내용을 저장한다.
- vi 편집기를 나온 뒤에는 source ~/.bashrc 를 실행하여 업데이트 한다.
9. 스칼라 설치
- 자바 설치와 마찬가지로 진행된다.
- 아래의 명령문을 넣어 스칼라를 설치한다.
(base) /opt$ sudo apt-get install scala -y
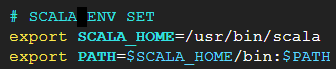
- vi 편집기를 열어 아까 수정한 코드 내용 하단에 이어 추가해준다.
# SCALA ENV SET
export SCALA_HOME=/usr/bin/scala
export PATH=$SCALA_HOME/bin:$PATH
- vi 편집기를 나온 뒤에는 동일하게 source ~/.bashrc 를 실행하여 업데이트 한다.
10. 스파크 설치
- 러닝스파크 교재에서 스파크 버전은 3.1.1 버전이기 때문에 해당 버전을 맞춰서 다운받는다.
(base) /opt$ sudo wget https://archive.apache.org/dist/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
(base) /opt$ sudo tar xvf spark-3.1.1-bin-hadoop2.7.tgz
(base) /opt$ sudo mkdir spark
(base) /opt$ sudo mv spark-3.1.1-bin-hadoop2.7/* /opt/spark/
(base) /opt$ cd spark
(base) /opt/spark$ ls
LICENSE R RELEASE conf examples kubernetes python yarn
NOTICE README.md bin data jars licenses sbin
- Spark 설치에 대한 환경변수를 설정한다. (이전 vi 편집기에서 수정한 내용에 이어서 입력)
- your_id 부분은 각자 계정에서 '@' 이전의 글자로 각자 id로 바꾸어 넣는다.
# SPARK ENV SET
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/home/your_id/miniconda3/bin/python
11. PySpark 설치
- 환경변수 설정이 끝난 후, pyspark 버전에 맞춰서 설치를 한다.
(base) /opt$ pip install pyspark==3.1.1
12. PySpark 실행
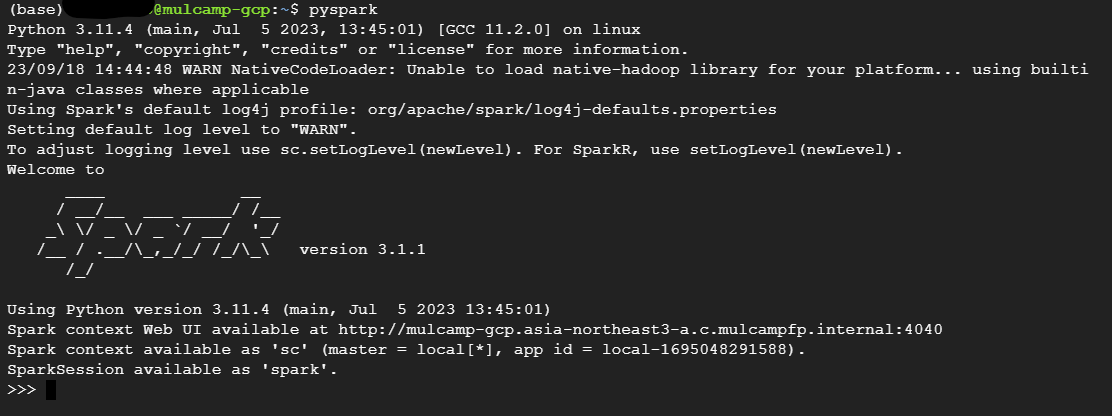
- PySpark를 실행한다.
(base) opt/spark$ cd $HOME
(base) $ ls
(base) $ pyspark
Python 3.11.4 (main, Jul 5 2023, 13:45:01) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
23/09/18 14:43:35 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.1
/_/
Using Python version 3.11.4 (main, Jul 5 2023 13:45:01)
Spark context Web UI available at http://mulcamp-gcp.asia-northeast3-a.c.mulcampfp.internal:4040
Spark context available as 'sc' (master = local[*], app id = local-1695048218211).
SparkSession available as 'spark'.
>>>
13. Jupyter Notebook 설치 및 설정
- Jupyter Notebook 를 설치한다.
(base) $ conda install jupyter notebook
- Jupyter 설정을 하기 위해 config 파일을 생성한다.
- 생성 후 vi 편집기를 연다.
(base) $ jupyter notebook --generate-config
Writing default config to: /home/your_id/.jupyter/jupyter_notebook_config.py
(base) $ cd /home/your_id/
(base) $ vi ~/.jupyter/jupyter_notebook_config.py
- vi 편집기를 열면 아래와 같은 코드를 찾아서 변경한다.
- vi 편집기에서 특정 글자를 찾기 위해서는 '/' 를 입력 후 검색어를 입력하면 된다.
- ex) /allow_root, /ip =
- 검색 후 맞는 문자열이 나오면 Enter 하고 i를 누르면 수정이 가능하다.
## Whether to allow the user to run the notebook as root.
#c.NotebookApp.allow_root = False
c.NotebookApp.allow_root = True
## The IP address the notebook server will listen on.
#c.NotebookApp.ip = 'localhost'
c.NotebookApp.ip = '0.0.0.0'
- 터미널에 jupyter notebook 입력해 실행하면 포트번호와 토큰번호를 알 수 있다.
(base) $ jupyter notebook- 이를 확인한 후 인스턴스의 외부 IP주소를 복사해서 URL에 입력
- 이어서 포트번호 ':8888'를 URL에 입력하면 아래의 화면처럼 접속이 가능하다.
- 간혹 포트번호가 8888이 아닐 수 있으니 터미널에 나온 값을 잘 확인할 것!
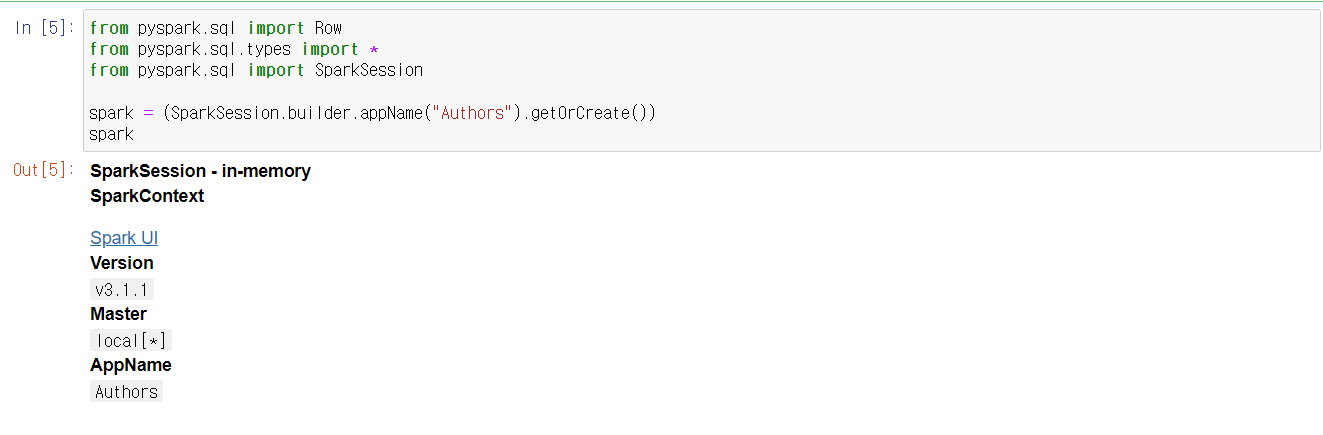
14. 테스트 코드
- 주피터 화면에서 New를 클릭해 새로운 python 노트북을 연 후 pyspark 버전을 확인해보자.
import pyspark
pyspark.__version__
- 아래의 샘플 코드를 실행한다.
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark.sql import SparkSession
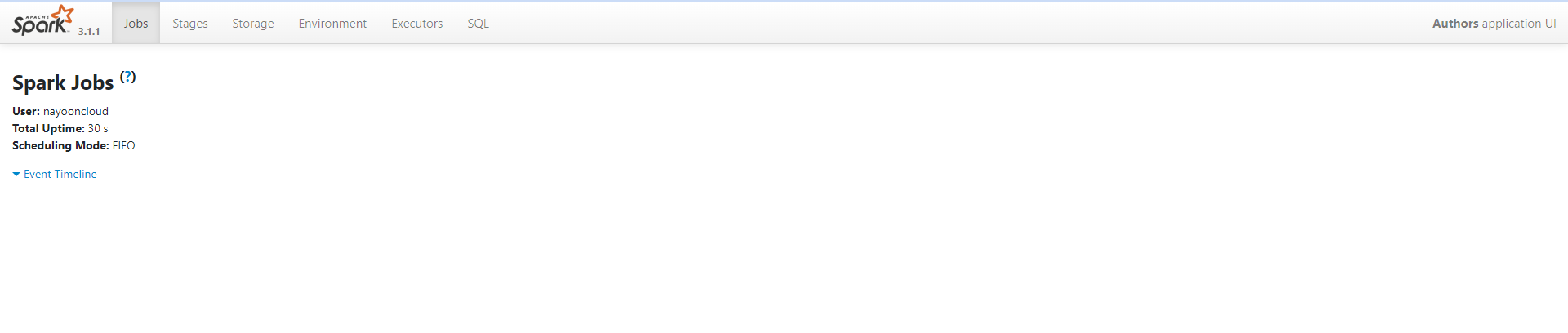
spark = (SparkSession.builder.appName("Authors").getOrCreate())
spark
- Spark UI도 확인해본다.
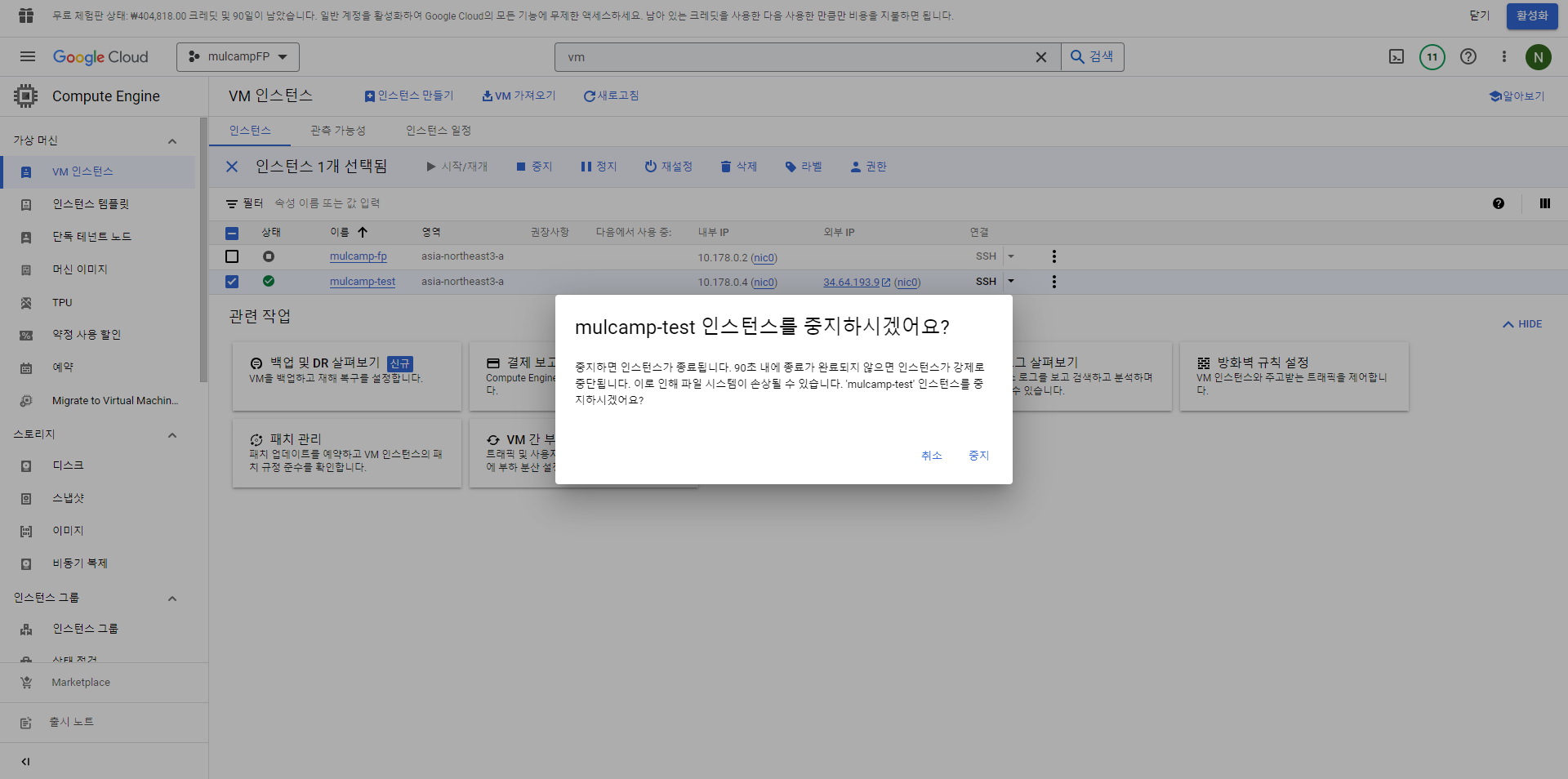
*인스턴스 중지
- 테스트가 완료가 되었다면 인스턴스를 반드시 중지하여 비용이 나가지 않도록 한다.
'Setting' 카테고리의 다른 글
| AWS EC2 접속 (with VScode) (0) | 2023.10.16 |
|---|---|
| AWS EC2 접속 (with pem & ppk file) (0) | 2023.10.16 |
| PostgreSQL 설치, 환경변수 설정 - Window 11 ver. (0) | 2023.10.12 |
| Pycharm 가상환경 생성 + Django 설치 (Github에 있는 프로젝트 가져오는 것부터 차근차근) (0) | 2023.07.25 |



