다음 글은 데이터리안 5월 세미나를 듣고 남기는 후기입니다.
목차
0. 세미나 소개
1. 생성형 AI 분석 활용 사례
a. NBA 선수가 되기 위한 조건은?
2. 생성형 AI와 함께하는 분석의 미래
a. 개인 관점
b. 조직 관점
3. 후기
4. 참고
0. 세미나 소개
이번 5월 세미나는 [생성형 AI와 함께하는 데이터 분석가 커리어] 라는 주제이다.
Chat GPT, Clova X를 비롯한 생성형 AI 시대에서 데이터 분석의 미래를 전망해 본다라,,
꽤나 구미가 당겼기 때문에 고민 없이 세미나를 신청했다.
참고로 필자는 과제를 할 때 생성형 AI를 이리저리 잘 사용하는 사람 중 하나이다.
특히 Chat GPT는 질문을 잘 만하면 답변의 퀄리티가 좋아지는 걸 요새 느끼고 있다.
근데 퀄리티가 좋아지는만큼 내 자리를 위협할 수 있다..? 라는 생각을 하니 싸-악 정신차려지게 된다.
아무튼 미래를 미리 대비하는 건 좋으니까,
이번 세미나를 통해 네이버의 Data & Analytics 조직의 리더이신 김진영님과,
데이터리안의 데이터 분석가님들이 나누는 이야기를 듣고 아래 항목 중심으로 글을 정리해보려고 한다.
1. 생성형 AI 분석 활용 사례
2. 생성형 AI와 함께하는 분석의 미래
*세미나 내용에 대해 더 알아보고 싶다면?
[생성형 AI와 함께하는 데이터 분석가 커리어] 2024년 5월 세미나 다시보기
5월 세미나 슬라이드와 1부 강연 영상을 다시보실 수 있어요!
datarian.io
1. 생성형 AI 분석 활용 사례
a. NBA 선수가 되기 위한 조건은?
노력만 하면 누구나 NBA 선수가 될 수 있는걸까?
굉장히 흥미로운 주제의 이 분석은 ChatGPT를 활용한 분석 사례이다.

결론은 불가능은 아니지만 매우 어렵다고 한다.
NBA 선수의 아들이 아닌 177.8cm의 미국인이 NBA 선수가 되려면 약 0.0000001%확률인 반면, (확률 극악,,)
NBA 선수의 아들이면 2.3%로 확률이 갑자기 확 올라간다.
그리고 키가 2m 10cm이 넘으면, 또 쌍둥이 형제가 NBA 선수면 확률은 더 커진다.
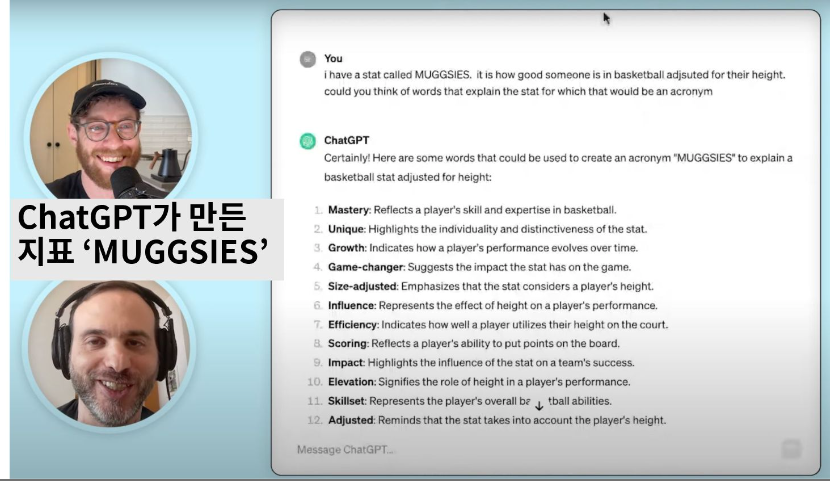
그리고 Chat GPT는 이 분석 결과를 바탕으로 NBA 선수의 역량을 지표로 만들었다.
각 지표의 앞 글자를 따서 'MUGGIES'라는 이름도 짓는 작명가다운 면모를 보여준다.
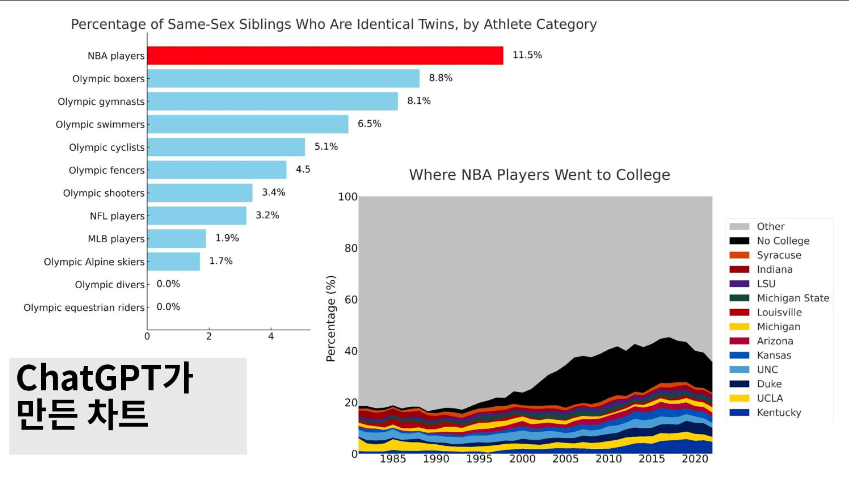
운동 선수 중 동성인 일란성 쌍둥이의 비율 중 NBA 선수가 가장 많이 차지한다는 결과의 막대그래프,
NBA 선수들이 많이 간 대학교를 나타내는 영역 그래프 등
포인트 컬러를 사용해 시각적으로 인상적인 차트도 만들 줄 안다.
특히 저 대학교 그래프의 색깔은 각 대학의 대표 색깔을 알아서 맞춰주는 센스가 돋보인다.
*사담*
궁금해서 찾아본 NBA 1등 대학..
2024년 기준, 켄터키 대학교에서는 132명의 가장 많은 NBA 선수를 배출했다고 한다.
(명문켄대...)

그외에도 Chat GPT는 단순한 분석 및 통계 작업을 준수하게 수행하고,
자연어 이해를 바탕으로 데이터 클리닝 및 인코딩을 도와준다.
즉, 단순 코딩은 GPT에게 맞겨 분석 업무에 집중하게 해줄 수 있다.
반면, 제안한 가설이나 결론은 대부분 상식적인 수준이고
작성한 코드에는 오류가 있을 수 있어 꼼꼼히 검수해야한다.
(이 부분은 필자도 지난 과제를 하면서 뼈저리게 느낀 Chat GPT의 단점 중 하나이다.)
즉, 생성형 AI를 더욱 잘 활용하기 위해서는
잘 질문하는 법부터 알아야 한다.
분석 요구사항을 명확하게 표현하고, 중간 중간 생각할 여유를 두어 질문하는 게 좋다.
2. 생성형 AI와 함께하는 분석의 미래
a. 개인 관점

AI가 분석가 개인에게 미치는 영향은 무엇일까?
이에 대해 전문가들은 번역하는 수준의 분석은 이제 AI에게 대체되고
전문가는 새로운 문제와 방법론을 개발하는, 좀 더 높은 수준의 역할을 맡을 것이라고 전망한다.
그러기 위해서는 소프트 스킬의 중요도가 필연적으로 올라간다.

물론 아직은 낮은 수준의 코딩을 구사하고 있지만 데이터 분석 플랫폼 자체에 AI를 탑재하는 순간이 온다면
데이터 분석에서 기술적 역량의 중요성은 점점 줄어들게 될 것이다.
따라서 문제를 해결하고 업무 결과를 평가하고 가이드할 줄 아는 PM, TL 같은 역할을 더 맡게 된다고 본다.
b. 조직 관점

그럼 AI가 조직에 미치는 영향은 어떻게 될까?
우선 조직 상황에 따라 달라질 것이다.
대부분의 조직은 늘어난 분석 역량을 잠재적인 문제 해결에 활용할 것으로 전망된다.
즉, 확실히 눈에 보이는 문제에만 데이터 분석을 했다면
이제는 그 가치가 명확히 보이지 않는 문제 해결에도 활용한다는 뜻이다.
(분석의 니즈가 크지 않은 조직이라면 분석 역량을 덜 활용하겠지만 말이다.)

또한 개별 데이터 팀이 따로 있기 보다는 각 스쿼드나 팀별로 임베딩된 분석가의 비중이 늘어날 것이다.
분석가의 업무가 각 조직의 KPI나 문제 해결에 더욱 집중하게 될테니 조직과 가까이 하게 되는 것이다.

이 부분이 되게 인상깊게 느껴졌는데
앞으로 모든 기술 스택은 사람이 편하게 만들기 보다는 AI에게 편하게 만드는 것도 염두에 두어야한다는 것이다.
지금 SQL 같은 경우는 사람에게 편한 방식으로 만들어진 툴이지만
AI가 직접 한다면 굳이 사람에 맞춘 툴일 필요가 없기 때문이다.
AI라는 고객 입장도 생각해야한다니, 세상이 너무 빨리 바뀌는 것 같은 느낌이 든 대목이었다.

정리하자면, 앞으로 데이터 분석/사이언스의 커리어를 준비하기 위해서는
소프트 스킬과 도메인 지식이 핵심 역량으로 자리 잡게 될 것이다.
그치만 AI가 한 업무 결과를 평가할 수 있어야하기 때문에 어느 정도의 기술적인 이해는 여전히 중요하다.
3. 후기
위의 정리한 내용은 1부까지였고 2부부터는 데이터 분석가 커리어 성장과 관련된 Q&A 세션이 이어졌다.
세션을 들으면서 주니어 분석가로서의 핵심 역량을 키우기 위해 어떤 것을 해야하는지 조금 감을 잡을 수 있었다.
그리고 아직 시니어 단계는 아니지만 미리 시니어가 됐을 때 어떤 업무를 하게 될 것인지,
더 넓게 그려보는 일도 중요하다는 것을 알게 되었다.
말이 나온 김에 생각해보자면,나의 시니어 단계는 30대 중반 ~ 후반이 될 것 같다.
30대 중반이 딱 내 경험이 견고해지는 시기가 될 것인데,이 때 커리어 점프를 하기 위해 몇가지 아이디어가 떠오른다.
- 비슷하지만 조금 다른 영역으로 이직?
- 죽기 전에 꼭 해보고 싶은 프로젝트 아이디어에 과감하게 도전?
아무튼 시니어가 되어서도 혼란스럽지 않으려면
앞으로 데이터 분석가로서 어떤 커리어를 그려가야할지 설계도를 잘 그려야겠다는 생각이 들었다.
그 과정이 오래 걸리더라도 내게 아마 큰 도움이 될 것이라고 굳게 믿는다.
오늘도 유익한 세미나를 열어주신 데이터리안에게 감사드리며,,이만 글을 마치겠다.
4. 참고
[데이터리안]
[생성형 AI와 함께하는 데이터 분석가 커리어] 2024년 5월 세미나 다시보기
[추가 참고]
생성형 AI 시대의 데이터 사이언스